"with" loss of generality
04:40 04/06/04
ピーステーブル
PieceTable とも言う。文字列の Piece(小片)を繋げて、
一つの巨大な文書を表現する方式。
検索すると引っかかる文書のほとんどが AbiWord 関係なので、
このワープロソフトの主要な内部データ構造ということなのかな。
他に、MS-WordやOpenOffice.org関連の文書にも登場していて、
基本的に単なるテキストエディタよりは、文字に付加情報をくっつける系の
編集ソフトに使われる場面が今のところ多いみたいです。
余談ですがAbiWordは、綱渡り的にですがBeOS版の開発が続いている貴重なワープロソフトなのです。感謝感謝。
概要
ファイルを読み込んだとしましょう。ABCDEFG、という7文字のファイル。
とりあえず、7文字分のOrigという名前のバッファを用意して、そこに格納します。
それと別に、Addという名前の空のバッファも作っておきます。
こっちはサイズは適当で、足りなくなったら適宜拡大すると言うことで。
また、バッファの他に、表を一つ持っておきます。最初は、Orig 1~7
(Origバッファの1から7バイト目まで、の意味)という列が一つだけの表。
この表が、実は、"PieceTable" と呼ばれる物です。
Orig: [A B C D E F G]
Add : [* * * * * * * * * * * * * * * * * * * *]
===============
|| Orig 1~7 ||
===============
さて、編集してみましょう。DとEの間に、数字の1を挿入します。
Orig: [A B C D E F G]
Add : [1 * * * * * * * * * * * * * * * * * * *]
===============
|| Orig 1~4 ||
|| Add 1~1 ||
|| Orig 5~7 ||
===============
挿入する文字は、Addバッファの先頭から順に書き込みます。Origは書き換えません。
PieceTableの「Orig 1~7」は分割して、間に追加分を挿入して3列の表にします。
これで文書全体が「Origの1~4バイト目」、「Addの1~1バイト目」、
「Origの5~7バイト目」であることを表現します。
編集を続けます。さっきの場所に、"234"と続けて入力します。
Orig: [A B C D E F G]
Add : [1 2 3 4 * * * * * * * * * * * * * * * *]
===============
|| Orig 1~4 ||
|| Add 1~4 ||
|| Orig 5~7 ||
===============
Addバッファにどんどん書きためます。今度はPieceTableを分割する必要はなくて、
上から2番目のエントリをちょこっと書き換えればOKです。このように、
同じ箇所への連続挿入は非常に高速です。
ここまでの編集の結果、文字列は"ABCD1234EFG"となっています。
次に、BとCの間に"lalala"と挿入してみます。さっきと同じように、
入力データはAddバッファに溜めます。PieceTableの挿入箇所を分割して、挿入。
Orig: [A B C D E F G]
Add : [1 2 3 4 l a l a l a * * * * * * * * * *]
================
|| Orig 1~2 ||
|| Add 5~10 ||
|| Orig 3~4 ||
|| Add 1~4 ||
|| Orig 5~7 ||
================
削除します。"ABlalalaCD1234EFG" の、"34E"を削除するには…
Orig: [A B C D E F G]
Add : [1 2 3 4 l a l a l a * * * * * * * * * *]
================
|| Orig 1~2 ||
|| Add 5~10 ||
|| Orig 3~4 ||
|| Add 1~2 ||
|| Orig 6~7 ||
================
バッファの方には手を加えずに、PieceTableの方を書き換えます。
もっと大きな範囲の削除であれば(例えば"CD1234EF"を削除、であれば)
PieceTableの列が一列消えて、短くなることもあります。
いずれにせよ、ユーザから見て削除されたはずの "34" や "E"
の字はメモリに残ったままになります。
"lalala" の後ろに "ruru" と付け加えましょう。
Orig: [A B C D E F G]
Add : [1 2 3 4 l a l a l a r u r u * * * * * *]
================
|| Orig 1~2 ||
|| Add 5~14 ||
|| Orig 3~4 ||
|| Add 1~2 ||
|| Orig 6~7 ||
================
最後に挿入を行った箇所の直後だったので、Addバッファに書き溜めたら、
あとはPieceTableの値を書き換えるのみです。分割は要りません。
"ABlalalaruruCD12FG"
特徴
挿入・削除の操作に関しては…
- 同じ箇所への連続挿入はギャップバッファと同様、高速です。
- Piece をまたがない削除は位置によらず高速です。
これは、例えば直前に入力した字をBackSpaceで消すとか、
オリジナルファイル中の数行をまとめて削除する、
と言ったよく典型的な削除動作をカバーしています。
- Piece をまたぐ削除や、新しい位置への挿入は PieceTable
への削除/挿入操作となるので、
性能はPieceTableの構造に依存します(後述)。
- 一つ一つの Piece の実装は配列やVectorで十分(Origバッファは書き換えない、
Addバッファは末尾への追記しなしない)なので、
Piece内は完全にランダムアクセス可能です。
その他に、
- ロープ同様、末端の文字列データ(Piece)は、
一度作ったら書き換えません。Immutableです。削除すらされません。
Addバッファは後ろへ後ろへ伸ばして行くのみです。
- 削除したデータもすべてメモリに残すというのは無駄が大きい、
と思われるでしょうか?これは、実は全くそんなことはありません。
多くのエディタが実装している 「メモリの許す限り無制限Undo」という機能を
実現するには、どの道、全ての入力データを保持しておかないといかんのです。
PieceTable法の場合、全ての入力を一列に、
メモリを隙間無く有効利用した状態で格納できています。
- 元操作が高速だったら、そのUndo/Redoは、PieceTable
のインデックス操作で済むのでこれまた楽です。
あと、エディタはともかくワープロなど、
一部分の文字に色を付けたりサイズや属性を変えたり、
テキスト以外の絵や表を挟み込んだりする用途に応用できるのも特徴です。
例えば絵を挟み込む方は、PieceTableのエントリとして、Orig, Add の他に
Img という種類の列を入れられるようにして、絵を挿入する位置には Img
エントリを入れとけばOK。文字の属性の方は、PieceTable に バッファ種/バイト位置
の他に、属性、を入れる3つ目の欄を用意しとけばOK。
実装
で、問題は、OrigやAddを格納している表のデータ構造をどうするかな、
という点に絞られます。このデータ構造に求められる機能を、
もう一度整理してみましょう。
- 任意箇所への挿入・削除が速いと嬉しい。これが速ければ、
連続挿入や小さな削除以外も高速化されますね。
- 場所を指定して対応するPieceを見つけだす処理も速いと嬉しい。
挿入場所を指定されたとき "どのPieceを分割すればいいか"
の決定に時間がかかっては元も子もないですから。
さて、VectorでもLinkedListでもうまく行かない構造ですが、
どうしたものでしょうか。現実には、
「挿入削除が遅いのはエディタとして致命的だろう」という理由と、
「テーブルのサイズは文書全体と比較しても短いことが多い(最初なんか、
文書の長さにかかわらず長さ1だ!)」などの理由から、LinkedList
が最も一般的に使われています。
…って、なんかよく似たセリフを1週間前に書いたような気が。
そう、ここで再び 「テキストエディタに向いたデータ構造は何か?」
という問題が現れました。でも、今度は私たちは答えを知っています。
OrigやAddを格納している表は、例えば、"ギャップバッファ"
を使うと効率よく処理できます。"ロープ"…いやいっそのこと、
"ピーステーブル" を使っちゃうのも面白いかもしれませんね。
(一文字書き換えに相当する操作が多発するはずなので、
後二者は実際には向かないと思いますが(^^;)
22:09 04/05/31
心の端を一言に
今のこの心境をひとことで述べるとするならば、「眠い」。ねむぃ
Pieceful
掲示板で "Data Structures for Text Sequences" (1998)
という論文を教えていただきました。配列、LinkedList、ギャップバッファ、
ピーステーブルなどなどを比較して、テキストエディタに適切なデータ構造を探ろう、
という話。特にピーステーブルについて詳しいです。少なくとも、
ここ数日私が書いてる内容よりはキチンとまとまってますので興味のある方は必読です。
あと、3日前にリンクした先のTaktyさんの手になる
"ギャップ・バッファの解説" という文書が公開されてました。
あー、PieceTableについてまだ書いてないのは、
面白いからもったいぶってるとかではなく、
単にサボってるだけなので特に期待しないが吉です。次くらいには書きますよー。
18:41 04/05/29
ロープ
Rope / Cord / ロープ / コード とも言う。文字列 = String = 紐
を強化したらロープになっちゃったらしい。
コード(電源とかのコードね)というのはロープより少し軽い分機能が少ないのですが、
本質的な部分は全く同じなのであんまり区別しません。
かの有名なBoehmGCのソースコード中のcordディレクトリが、Cによるコードの実装です。
見てないけど、GCの中のどこかで使っているんでしょうか。
C++使いの人には、SGI版STLのropeクラステンプレートとして知られています。
論文(1995) が出てます。
特徴としては、文字列と文字列の結合が猛烈に速いのと、部分文字列を切り出す演算
(いわゆるsubstring)がかなり速いのと、
文字列のコピーが恐ろしく速いという点があります。単純な CopyOnWrite
よりも構造的にデータ共有をするため、文字列A と Aをちょっと書き換えた文字列、
の間でデータ共有ができてメモリ消費量が減らせます。
ただし、1文字挿入は、substringで前後にわけて1文字を挟んで2回結合、
という手段で実現されるので、いくらsubstrや結合が速いといっても遅いです。
データ共有を制限すれば GapBuffer
のような連続挿入は速い構造にもできると思いますが、
実際の実装がどうなっているかは不明。
概要
えーと、論文からの引用です。下の図が、ropeの全てを表しています。
"The quick brown fox" という文字列の表現例。
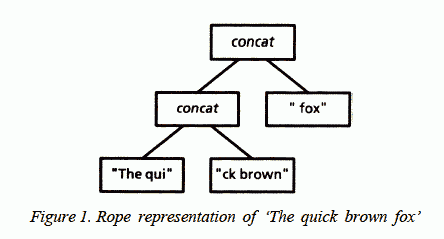
Ropeは、葉が文字列、ノードが[concat]という名前の二分木です。
文字列Aと文字列Bを結合しろと言われたら、実際の結合はせずに、
左の子がA、右の子がBの新しい[concat]ノードを作って返します。瞬殺です。
Substring処理は、切断したい場所までRopeの木をサクサクと降りていって、
スパッと切ってから、また元の木の葉文字列をconcatして木を作っていきます。
二分木がバランスがとれていれば、葉の数Nに対して O(log N) で終わる処理です。
二分木をバランスさせるアルゴリズムとしては、AVL木や赤黒木(Red-Black-Tree)
などが知られていますのでその辺を参照のこと。
Ropeでは、一度作った葉ノードは基本的に書き換えません。
Substringでスパッと切るというのも、
切りたい葉文字列の左半分を指すポインタのペアと右半分を指すポインタのペアを
作るだけになります。(こうやって配列のど真ん中へのポインタを作って
共有しまくるデータ構造なので、BoehmGCのデモとして使われているのかも。)
特徴
- substr, concat がO(log N)。
- 位置を指定してのアクセスはO(log N)。
- てゆーかわりと何でもO(log N)
- 文字列を端から順になめるイテレータは、要するに木のイテレータなので、
std::setやstd::mapのもののようなパフォーマンス。
- JavaでいうところのImmutable Objectである。
あるいは関数型言語的な、書き換えを行わないデータ構造であると言える。
葉への書き込み禁止で、そのせいで一文字編集が遅いというのは、
テキストエディタに使うにはどうなのかなぁ…という感想。
データ共有を頑張るので、Undo/Redo
ヒストリを単純な全文字列のリストで管理できて簡単なのでエディタにも向いている、
的な主張は見た記憶があります(不確か)。
むしろstd::stringを置き換える、普段の文字列として使った方が良さそうな印象です。
あと、葉文字列は決して書き込まれないので、
そこが本当にC言語的文字列バッファである必要はなくて、
例えばメモリマップドなReadOnlyファイルをそこに置いてもいいし、
極端な話、インターフェイスの統一さえできれば、
呼び出すと文字列を返す関数だって構わない。
備考
小ブロックをリンクリストじゃなくてバランス二分木を使って並べる方式と言えます。
リストでなく二分木なのでランダムアクセスがO(log N)になりますが、
どのくらい嬉しいか悲しいかは謎。
あと、Expression Template で文字列結合をしよう、と思ったことのある人は、
ETが生成する中間データ構造が rope
によく似通っていることに気づかれたのではないかと思います。そんな共通点もあり。
ついでに、これ、完璧に関数型のデータ構造なんですけど
ML や Haskell での実装ってどなたかご存じないでしょうか?
> そっち方面な方々。Schemeでは見たことがあるんですが…。
17:35 04/05/29
ギャップバッファ
GapBuffer / GapVector / 空間バッファ / ギャップベクタ とも言う。
私はGreenPad で使ってます。
GreenPadの場合、「行=VectorOf文字, 文書=GapBufferOf行」という構成。
ほとんどの場合1行なんて100文字以下なので、
Vectorでコピーしまくっても十分速度が出ます。
凝ったことはしない方が吉。行数はもっとずっと長くなるかもしれないので、
Vectorよりは多少挿入削除に強い、GapBufferを使ってみました。
時々「行=GapBufferOf文字、文書=LinkedListOf行」で使う、
という解説を目にすることがあるんですけど、
その構成は正直意味がわからんです。行じゃなくてもっと大きい単位なら、
この構成も有効だと思います。
ソース読んだことないので詳しくは知りませんが、Emacsでも使われているらしいです。
概要
とりあえず最初は、適当なサイズのメモリを確保しておきます。以下では、使ってないメモリ領域は*の色で、使っているメモリ領域は黒字で、最近書き込んだメモリ領域はEのような背景色で書いてます。
[* * * * * * * * * * * ]
先頭から順に、
ABCDとデータを入れてみましょう。メモリに順に書き込むだけ。普通。
[A B C D * * * * * * *]
次に、BとCの間に文字列を挿入しようと思います。この時は、まずそこに隙間を作る。
つまり、CDを、確保したメモリの一番後ろに移動。移動って言うかコピー。
[A B C D * * * * * C D]
移動したら、挿入処理ができます。Eと一文字入れてみます。普通に隙間部分のメモリを書き潰すだけ。
[A B E D * * * * * C D]
さらにFG、と二文字挿入。隙間のメモリを書き潰し。
[A B E F G * * * * C D]
こんどは、CとDの間に何か挿入したくなりました。こんなときは、CとDの間に隙間を作成。要するに、Cを前の方に移動。
[A B E F G C * * * C D]
隙間を作ってからなら、書き込めます。例えばHI、と。
[A B E F G C H I * C D]
削除もしてみましょう。BからGまでを削除したい。そういうときも、まず、Bのところに隙間を作ります。BからIまでをごそっと移動することになります。
[A B E B E F G C H I D]
で、隙間を作ってからBからGを削除。削除というか、
隙間の終わりを意味するポインタをずらすだけ。
[A B E B E F G C H I D]
特徴
- 「○番目のデータが欲しい」要求には強い。Vectorほどではないですが、
隙間(ギャップ)のサイズ分調整すれば、
すぐにデータのメモリ上の場所が計算できます。
- 同じ箇所への連続した挿入、削除には強い。
どの位置でも一度隙間を移動させてしまえば、その後の挿入はコピー要らずです。
で、テキストエディタであることを考慮すると、普通は、
一度一カ所へ入力を始めたら、しばらくその位置の近辺への入力が続きます。
実際、このHTMLの編集中に私はもう30行くらい同じ場所へ連続挿入してます。
人間の行動特性を反映したデータ構造であると言われる所以。
実装上の注意
「配列1個 + 隙間開始のインデックス + 隙間終了のインデックス」
で表現します。隙間が0になったら別の大きなメモリを再割り当てして、
そこに全コピー。
特に削除のときの隙間作成のためのコピー量は工夫すると減らせます。
例えば上の例なら、GとCの間に隙間を作ってから削除、で十分。
二つ隙間を作っておいて、挿入に強い場所を二カ所に増やす、
という発展も考えられますが、これは手間が多い割にあんまり利益がありません。
上手くやらないと、油断すると二つの隙間が常に近くに集まってしまって、
意味がなくなったりもします。例外として、用途によっては、
「二個目の隙間は常にテキストの一番最後に固定」
としておくと末尾への追記が常に速くなって嬉しいかもしれません。
あと日本語環境だと、実際にテキスト入力が送られてくる時点ではなく、
ちょっと前、例えばユーザがIMEで変換を始めたら
裏でひっそり隙間空け作業をしておくという手があります。
[確定]キーが押される頃には隙間空け完了して待っているという寸法。
17:11 04/05/29
一般向け
テキストは、行がたくさん並んだ物です。行は、文字がたくさん並んだ物です。
このような「○○がたくさん並んだ物」をコンピュータ上で表現した物を、
"順序付きコンテナ"と呼ぶことにします。
順序付きコンテナの例としては、配列や、Vectorと呼ばれる構造があります。
こいつらは、メモリ上に、順番通りに物をキッチリしきつめて表現します。
特徴としては、
- 「100行目のデータが欲しい」とか「65536文字目の文字が知りたい」
という○番目のデータが欲しい、という要求に一瞬で応えられること。
メモリ上に詰めて置いてあるので、65536文字目なら、
使ってるメモリ領域の先頭から65536バイト先に入ってるに決まってますから、
そこから取ってくればOK、と。
- 「この文字とこの文字目の間に一文字挿入したい」といった挿入要求に弱いこと。
キッチリと順番にしきつめなきゃいけないので、
新しく1文字入れると、そこから後ろの文字全部を1文字分移動しないといけません。
同様に1文字削除したい、というのにも弱いですね。
- 例外的に、データの並びの後ろの方への挿入や削除は比較的速いです。
極端な話、一番後ろに1文字追記するなら、
そこから後ろに文字は存在しないので、特に何も移動しなくて構わないので。
他に、連結リスト、LinkedListなどと呼ばれる構造があります。
メモリ上には、データ一個ごとに、「データの内容と、
次のデータが置いてあるメモリ上の位置」を記録します。Vectorと違って、
隣あうはずのデータがメモリ上ではバラバラの位置に置かれていても気にしません。
書き込まれた[次はどこどこ]情報だけが頼り。
- 途中への挿入や削除が高速です。先頭の情報が ['a', 次のデータはhogehogeにある]
で、hogehogeには ['b', 次のデータはfugafugaにある]。fugafuga には…(略)…
という形でリストが記録されていたときに、'a' と 'b' の間に 'x'
を挿入したいと思ったら、1:メモリ上の適当な位置 puyopuyo に
['x', 次のデータはhogehogeにある]と書き込み。2:['a',hogehoge]のヤツを、
['a',次のデータはpuyopuyoにある]と書き換え。の2回の操作で全て完了。
ちょこっとリンクの張り替えをするだけで、コピーは全く必要ありません。
- 「65536番目のデータが欲しい」と言われたときには、逆に大変。
先頭から順に「次はこっち」「次はあっち」というのを65536回たどらないと、
どこに65536番目のデータが眠っているのかわかりませんので。
…と、まあ、VectorやLinkedListの改良版や、
全く異なる構造も含めて"順序付きコンテナ"は無数に考えられますが、
どれも一長一短あるわけです。となれば、
激しく順序付きコンテナを使うプログラムを書きたいときには、
使い方に応じた長所を持ったものをプログラマが適宜選ぶことになります。
テキストエディタ
さて、では、テキストエディタでテキストを格納するのに適した順序付きコンテナは?
選ぶ際には、エディタとして使うにはどんな操作が高速だと嬉しいか。
あるいは低速でも問題ないか。を考えます。
- 挿入、削除は遅いとイヤ。(エディタなんだから当然)
- 番号を指定してデータを取り出すのも速いほうがいい。
(例えば、行番号を指定してジャンプ。あるいは、
現在表示中のデータの行番号や、スクロールバーの表示を調整するのにも、
番号とデータの対応が速いと便利です。)
いきなりVectorでもLinkedListでもうまく行かない構造ですが、
どうしたものでしょうか。現実には、
「挿入削除が遅いのはエディタとして致命的だろう」という理由と、
「LinkedListでもわりと簡単に表示位置の行番号くらいは高速に記憶しておける」
などの理由から、LinkedList が最も一般的に使われています。
(※正確には、1行1行は文字のVectorで、
文書全体は行のLinkedListで表すのが一般的。
行単位で分けるのか何単位で分けるのか、という分割場所の選択も、
実はコンテナの選択と密接に絡んだ問題点です。)
まとめ
で、まあ、そういうわけで答えは出てるんですけど、
とゆーか、今時のマシンならVectorでも大して挿入遅く感じないので
ぶっちゃけあんまり悩む必要がないんですけど、
しかしこの世には色々な改良案があるので調べてみたりするわけです。
というわけで需要が全くなさそうですが、
あたりについて。次回に続く。
23:22 04/05/27
第4回XYZの1日目。行って発表したり話を聞いたりしてきました。
プレゼン資料が完成したのが発表開始の2時間30分前だったりしたので、
つまりなんというか、その、眠い。
村田さんのボヘミアン演説が生で聴けたのが楽しかったです。
PieceTable
ギャップバッファという文脈でGreenPadについて触れているページを見つけて、「そういえばこのデータ構造って、
Googleで探しても昔はきちんとした解説が見つからなかった覚えがあるなぁ」
と思い返しながらGoogleってみたら状況はほとんど変わってませんでした。
しかし収穫として JavaのAPIドキュメントが見つかって、
サイズの大きいテキストを格納するのに適した "ピーステーブル"
なるデータ構造が存在するという情報を入手。
聞いたことがない名前です。気になるので今度調べてみようと思います。
…PieceTableというページを20秒くらい眺めた限りでは、
ropeっぽい物、かな?
全然違うかも。あとでちゃんと読む。
00:48 04/05/27
『四季 冬』 読み終わり。
元々、本を読んだりゲームをしたりするときには、
あまり裏を読まないで素直に楽しむことにしているんですよ。少なくとも一回目は。
例えば推理小説だったら犯人当てとか考えないで、
謎解きのシーンでワトソン役と一緒に「おーそうだったのか」と驚きたいし、
自分の命を犠牲にして主人公を救ったと思われた仲間が
物語の最後の方で実は生き延びていたことが判明した、
そのシーンで「やっぱりね」なんて醒めていたくはないですし。
ノベルゲームを遊ぶなら感動する気満々でとりかかるし、
このエピソードとあのエピソードも後でこういう仕掛けで繋がるんだろうなぁ、
みたいな予測も出来るだけせずに読み進めます。
…で、まぁ普段からそんな感じなので当然なんですけど、なんで、この 『冬』
でこう話が締めくくられることに149ページ目に至るまで気づかなかったのか自分は。
思い返せばほとんど論理的帰結じゃないか。やられたー!!
内輪向け
WS1SとM2L-Strの違いって ∀P∃Q.(P⊆Q & P≠Q) 辺りかな?補足。
22:06 04/05/24
縁あって、
Veritak
というVerilogHDLシミュレータのサイトを眺めていました。
チュートリアルなどなど、読んでいて興味深い内容が多いです。
あれ、ハードウェア記述ってこんなに面白そうな世界でしたっけ。。。
CPU書きたくなってきたかもしれない。
プログラミングコンテスト
二つ、参加してみようと思ってる大会が近づいています。
どちらもインターネット上での大会なので簡単に挑むことができます。
…と、ここの読者さんの参加を煽ってみるテスト。
ICFP
Is your favorite programming language the best? Does it lead to better and
faster programs? Does it make programs easy to write and modify? Are you and
your friends the best programmers in the world?
Then prove it!
The Seventh ICFP Programming Contest。
世界標準時で、6/4 16:00 から 6/7 16:00 までの72時間勝負。
言語は問わず、何人チームでも可。
自分の腕と自分の好きなプログラミング言語のスゴさを証明してみせろ!!
というコンテストです。参加料や資格、事前手続きは特に必要ないので、
暇つぶし気分でプログラム組んで参加してみるもよし。
C++好きな人はC++で、C#な人はC#で、JavaScript、D、Ada、Io、
OCaml、Haskell、Java、SmallTalk…自分がこれだと思う言語を片手に是非是非挑戦を。
ICPC
ACM/ICPC 2004 Ehime。日本時間で、7/2(金) 16:30 ~ 19:30 開催。
こちらは国際大学生プログラミング大会の日本地区予選で、
大学1年以上修士1年以下の学生からなる3人チームのみが参加できます。
使える言語はC, C++, Javaのどれか。同じ大学の仲間を誘ってLet's Try!!
なお参加締め切りは6/25なのでお早めに。
23:45 04/05/21
二年前に 出会った二歳上の人を凄いなぁ、と思ったとして、
ここで2という数字に特定の意味はないわけだけれど、
つまり今の自分はその年齢に達しているわけだ。
で、振り返ってみると、全然追いつけていない。知識、知識、知識が足りない。
発想力とか集中力とか、そういった思考に必要な能力の全てが
単調減少し続けるのは昔から諦めているからよいとして、
積み重ねていけるはずのものさえ足りていない。何ともなぁ。
bookmarklet
西田くん(20 thu.)
の Drag for iframe というお気に入れっとがとても便利なので、
ついつい無駄にリンクを開きたくなっちゃって困るのでした。
これがとても自分の感覚にマッチするインターフェイスだと感じるのは、
開くためにクリックする位置と閉じるためにクリックする位置が同じで
わかりやすいからでしょうか。
23:49 04/05/19
カレーライスを作っていたときに、「普通のカレーじゃ面白くないなぁ」
と思ってしまったが最後、冷蔵庫内でたまたま最初に目に付いた
白滝1パックを入れてみたんですけど、
あまり普段のカレーから変化がなくてしょんぼりな日でした。
カレールー自体かなり味が強いから、
並大抵の食材では普通にカレーになってしまう模様です。
ただし結果的にスプーンで白滝を食べねばならぬというのが大変でした。
Shuriken
Shuriken Pro3 /R.2 が出るらしい。IMAPに移行しようかと考えてたとこなので、
これは自分はバージョンアップすべきかなぁ。
最近さわり始めた SquirrelMail
(PHP製のウェブメールソフト)もかなり面白く、
これに乗り換えるという手も考え中。
ウェブメーラって結局の所インターフェイス記述がHTMLでなされるので、
プラグインがかなり好き勝手にHTMLを吐いてリッチな UI
を実現してしまっているのがいい感じ。
20:55 04/05/17
blockquote
| No. | 書名 | 出版社名(略称) |
ISBN | 発売日 |
| 1 |
Boost C++ Library プログラミング |
秀和システム |
4-7980-0786-2 |
2004/05/11 |
| 2 | ... | ... | ... | ... |
cbook24.com 売れ行き良好書 2004年05月10(月)~2004年05月16(日)
えーと、えーと、ありがとうございます。すみません。
プログラム と 生成文法
昨日読んで 「すげー面白れー!」
と思った論文があったので紹介しようと考えていたのですが、
今日「すげーーー面白れぇぇぇぇぇeee!!!」発表を聞かせていただいたので、
そっちについて自分の理解したところを書いてみちゃいます。
…と思って色々書いたんだけど、
どう書いても自分の腕ではさっぱり面白さが伝えられないのでコメントアウト。
うーむ。
この論文
"Derivation of deterministic inverse programs based on LR parsing" (ps.gz),
R Glück, M Kawabe. についての話で、「入力を受けて計算して結果を返すプログラム」
を受け取ると、その逆計算をするプログラムを自動生成する試みの話。
なんと、逆計算と一見無関係に思われる、
テキストの構文解析の手法を使って実現する、というものだそうです。
興味のある方はぜひご一読を。
17:36 04/05/16
しかしなんだかんだで、2chで訪れた文章系スレ…いや、
PC上で読んだテキストデータの中で一番好きなのは(これも前に紹介しましたが)
だったりもして、これは一人の書き手の力かなぁ。
あと10年はこれを越える物に出会えない予感すらする。
D
mixins for D。とりあえず翻訳。
混ぜ合わせオーバーロードが出来なさそうなのはD言語の他の部分を見ても
Walterさんのポリシーっぽいから仕方ないと忘れることにすれば、
C++の言語設計に対する私の3番目の不満がDで解消されるっぽい。よっしゃ。
委譲じゃないのは残念ですが…。
本当は
class A { ... }
template B() { ... }
class C = A.mixin!(B) // C inherits A and has members of B
こうできて欲しかったんですけど。
template Mixer(alias ClassTmpl)
{ template mix(Module){alias mix ClassTmpl!(Module);} }
class A(alias _ : Mixer!(A)) : if ... {
mixin _;
...
}
微妙すぎ微妙すぎ。
23:28 04/05/15
ドアが左右ではなく上下に開く/閉まるならば、
駆け込み乗車が減るんじゃないかと唐突に思いつきました。
すきまに駆け込むには、こう、
ハードル跳びの前傾姿勢みたいにならないといけないのです。冗談ですが。
しかし、そんなことを考える人がパッと見ただけで既に3人もいるのが素敵です。
電車男
「めしどこか たのむ」
「>>98 ここまできてアニメチェックを忘れないお前が大好きだ。」
「でも、最初に勇気を出したのは、変わる前の自分。」
いや別に電車つながりなわけではないんですが、
『電車男』というスレまとめが面白すぎて一気に読み通してしまいました。
昔からw.l.o.g.を読んでる方はご存じでしょうが、私はこの手のに弱くて…
→ (1
2
3
4
5
6
7
8)
(1
2
3)
(290-)。
誰かが書いた物語として読んだとしてさえ、配された伏線が、小道具が、
なんと見事に回収されてゆくことだろうかと感動してしまうと思う。
それが、どこかの誰かの小さな事件と大勢の名無しさんが結びつく形で
紡がれているんだから不思議なものだなぁ、と。
