"with" loss of generality
01:23 04/07/30
Windows
Microsoftの人のLonghornの話を聴いていて、
Monad Shell の Commandlet を操るには文字ベースのシェルに拘る必要はなくて、
ストレートに GUI 化できるんじゃないかという気がしてきました。公開されたら
ME (Monad Explorer) 作ってみようっと。
Windows → 訳
Windows (2000以降?) で
[Alt]を押しながらテンキーの 1, 2, 6 を順に押してAltを離すと、
'~' が入力されます。
D言語 FAQ
うわ、初耳。1バイト文字の文字コードを直接打ち込めるみたいですね。
訳 → 本
[cppll:11018] <fyi> The Design and Evolution of C++
原著を読もう読もうと思いつつまだ買っていなかったのですけど、
翻訳が始まったらしい。わーい。
本
やねうらお氏の
新しい本
が出るそうな。おめでとうございます。
とりあえず、「ええー!!マジで?!」
09:24 04/07/28
「エキセントリック」って言葉は、なんだか時刻表トリックっぽい。
一角獣
Unicon - the Unified Extended Dialect of Icon
というプログラミング言語があるらしい。まったく知りませんでした。。。
パッと見で Icon との大きな違いは、
クラスが入ってオブジェクト指向できるようになった点でしょうか。
あと、ライブラリは更に練られているようです。
あ、クラスの循環派生ができる。
In many situations, there are several ways to represent the same abstract type.
Two-dimensional points might be represented by Cartesian coordinates x and y, or
equivalently by radial coordinates expressed as a distance d and angle r given
in radians. If one implements classes corresponding to these types there is no
reason one of them should be considered a subclass of the other; they are
interchangeable and equivalent.
In Unicon, expressing this equivalence is simple and direct. In defining
classes Cartesian and Radial we may declare them to be superclasses of each
other:
class Cartesian : Radial (x, y)
# code that manipulates objects using Cartesian coordinates
end
class Radial : Cartesian (d, r)
# code that manipulates objects using radial coordinates
end
Unicon Book (PDF) p.120
2次元平面上の点は、x,y座標で表すこともできるし、極座標で表すこともできる。
しかも、最初x,yで表した点を極座標を通して処理したいこともあるし、
極座標で保持しておいて、たまにx座標やy座標を使って処理したいこともある。
お互いをお互いのインターフェイスを通して扱いたいわけだから、
お互いにクラス派生させちゃえばいいだろう、ってところ。ほー。
23:27 04/07/26
オープンソースTMソフトウェアのライセンスとして…
- BSDライセンスを選択するということは、
「GPLのコードを取り込めない」
デメリットに繋がる。
- GPLライセンスを選択するということは、
「BSDライセンスのコードに取り込まれることができない」
デメリットに繋がる。
前者で困るのは開発する自分達だけれど、後者で困るのは、
開発したコードを使う未来のユーザ達。
自分は後者のデメリットの方を遙かに大きく感じるので、GPLとBSDLから選ぶなら、
BSDライセンスの方を自作ソフトに適用します。別の立場のソフトウェア開発者ならば、
また違う結論にたどり着くでしょう。GPLの方がベターな場合も、
もちろん多く存在するんじゃないかと思います。
"立場" っていうのは、ぶっちゃけた話、「何のためにソース公開すんの?」
という問いに対する答えのことです。私は「ちょいと面白いもの作ったので、
誰かが、これを使って他の面白いこと始めてくれたら嬉しいなあ」
というスタンスから公開していますから、
他のコードに取り込まれる機会が減るという選択は絶対に避けたい。
「ソースを見てもらうことで、改善案やパッチがユーザから提供されると嬉しい」
が理由なら、取り込めるコードの種類が多いライセンスを選びたくなるかもしれません
(自分は特にそう思わないので想像ですが…っていうか、"自分は GPL
以外でソースを提供したくないのでBSDLなソフトに対するパッチは出せない"
って人はごく少数だと思うので、この点ではほとんど差異はなさそうですが)。
「GPLで提供されているライブラリの機能を使った面白い応用を思いついたので実装」
が理由ならば、必然的にGPLを選ぶことになります。
私の"他人のコードに取り込まれることを優先"という立場は理解しにくい、
と言われることもあります。でもさ、自分の力量を棚に上げて妄想するならば、
機会があったら自分のプロジェクトからコードを切り出して
Boost やら
HAIKU やら
FreeBSD やら
の Contributor に名を連ねてみたいじゃないですか。
そうじゃなくても、自分で頑張ってコードを書いてパッチ管理して
せっせと完成度の高いソフトを作り上げる…よりも、「こんなの書いてみたんで、
あとの応用はみんなに任せた!」 って座して待つと、
ありがたいことに Veritak に WeBoX や XacRettCE など、
素晴らしいソフトに使っていただけたりして、楽でしかもメチャメチャ嬉し楽しい。
←怠け者
あー (^^;
稲葉君の陰謀的メールが届いた(笑)
碧天雑感
暗躍しております。
23:29 04/07/24
ぷるーにぇ と呼ぼう。
JPBE
ここで先週書いた検索の話をJPBE.netに載せていただきました。Kokiさんありがとうございます。
いいのが思いつかなかったので物凄く散文的につけたタイトルが
今となっては微妙に恥ずかしいのは、秘密。
23:21 04/07/23
数日前
ジュンク堂を歩き回っていて、
『時をかける少女』 がマンガ化されてるのを知りました。
これは買わねば!と思ったけど、第1巻の方が見つからなかったのでとりあえず保留。
Amazonのレビューによると物語のアレンジもされているそうで、気になります。
で、そのまま別の階に行って、目当ての
『データ構造とアルゴリズム』を入手。
ボロノイ図/ドロネー図関係のアルゴリズムをちゃんと把握しておかないと…
と考えていた頃に著者である杉原厚吉氏の講義を聴いてえらく面白かったので、この本を購入することにしました。
ちなみに面白いと思った講義の内容は、氏のサイトの "幾何計算で困っている方へ"
に書かれているような内容で、"誤差が発生しても破綻しない幾何計算手法"
についてでした。
読んでみると "カーペンターズ・アルゴリズム" と題したコラムが楽しくて、
例えばグラフの最短路を求めるアルゴリズムを「重りと紐を使って
実際にグラフ構造を工作して、始点の重りと終点の重りを持ってピンと張る」
と、色々と実世界の手作業でアルゴリズムを実現しちゃってます。
よく知ってるはずの問題に対する見方が変わりました。
あとは、『コミック星新一 空への門』。"空への門" と "程度の問題" が Good。
01:49 04/07/20
JavaScriptの小技シリーズ第一弾:
「Memoization Rules.」という文章を書き始めてたんですが、
本質的な部分でこれ以上ないほどこちらの記事とかぶっていることに気づいたので破棄。
Memoizationはある種の問題に対して非常に便利で、どのくらい便利かというと、
Memo関数が書けない言語で動的計画アルゴリズムを書く気が全くおきなくなるくらい。
20:40 04/07/19
そうそう、数日前、我が家に新しいメンバーが増えました。

かき氷器。(¥1600)
いや、これはその、昔からの憧れのアイテムでして。だってあれだよ?
海の家に行ったりしなくても、家でお手軽にかき氷作れちゃうんですよ?凄いじゃん。
夏になったら…と心に決めていたので、とうとう買ってしまいました。
三種の神器
昔からの憧れのアイテムというと実は他に2つあって、その一つは、
ポップアップトースター。かき氷器といいこれといい、
普通に今すぐ買える品物じゃないか、とお思いかもしれません。確かにその通り。
でも、こいつらってなんか楽しくないです?
風物詩的というかシンボル的というかステレオタイプ的というか典型的というか、
その"いかにも"っぽさが素晴らしい。
最後の一つは、
ガラスのチェスセット。
この思わず「レイトレーシングしたいっ!」と感じる心をどうしたらいいのでしょうか
<変。そうでなくても、綺麗ですよね。
01:41 04/07/16
検索は便利だという話。
研究室の自分用マシンは、Zeta
というOSを入れて使っています。学友らから「なんでそんなマイナーOS使っとんねん」
って突っ込みがしょっちゅう入るのですが、
大勢が使ってるものを使うなんてつまんない…という理由は棚に上げておくと、
このOSの扱う BFS というファイルシステムが実に便利だから、なのです。
BFS(Be File System)は元々は BeOS
用に開発されたファイルシステムで、後継であるZetaに引き継がれているものです。
その最大の特徴は、ファイルに様々な"属性"を追加することができて、
その"属性"に関する高速な検索ができること。
ファイルシステムの検索機能というと
「階層構造できっちり整理するから自分には検索なんて不要」
という方も多いと思います。が、私はどっちかというと、
「なんでも検索で見つけられるんだからそんなに頑張って階層化しなくても」
派でして。よく行くウェブページに飛ぶときなんかでも、
ブラウザ"お気に入り"はあんまり使わないでGoogleの "I'm Feeling Lucky"
機能を愛用してたりします。
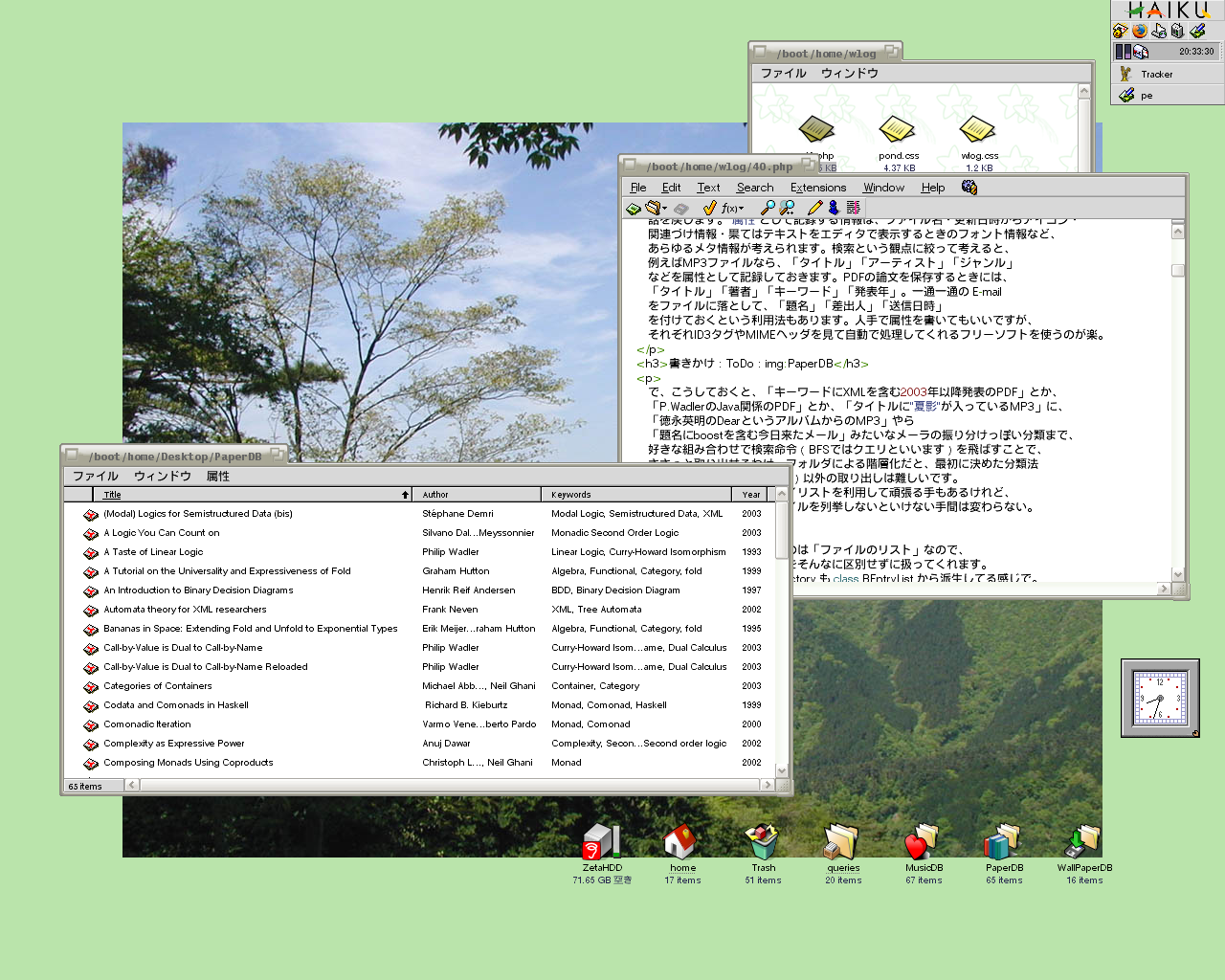
話を戻します。"属性"として記録する情報は、ファイル名・更新日時からアイコン・
関連づけ情報・果てはテキストをエディタで表示するときのフォント情報など、
あらゆるメタ情報が考えられます。検索という観点に絞って考えると、
例えばMP3ファイルなら、「タイトル」「アーティスト」「ジャンル」
などを属性として記録しておきます。PDFの論文を保存するときには、
「タイトル」「著者」「キーワード」「発表年」。一通一通の E-mail
をファイルに落として、「題名」「差出人」「送信日時」
を付けておくという利用法もあります。人手で属性を書いてもいいですが、
それぞれID3タグやMIMEヘッダを見て自動で処理してくれるフリーソフトを使うのが楽。
 PDFに色々属性を付けているの図
PDFに色々属性を付けているの図
で、こうしておくと、「キーワードにXMLを含む2003年以降発表のPDF」とか、
「P.WadlerのJava関係のPDF」とか、「タイトルに"夏影"が入っているMP3」に、
「徳永英明のDearというアルバムからのMP3」やら
「題名にboostを含む今日来たメール」みたいなメーラの振り分けっぽい分類まで、
好きな組み合わせで検索命令(BFSではクエリといいます)を飛ばすことで、
ささっと取り出せるわけ。フォルダによる階層化だと、最初に決めた分類法
(著者毎、ジャンル毎、etc)以外の取り出しは難しいです。
シンボリックリンクやプレイリストを利用して頑張る手もあるけれど、
それだって、手作業でファイルを列挙しないといけない手間は変わらない。
クエリもフォルダも表すものは「ファイルのリスト」なので、
かなりのアプリが、この二つをそんなに区別せずに扱ってくれます。
class BQuery も class BDirectory も class BEntryList から派生してる感じで。
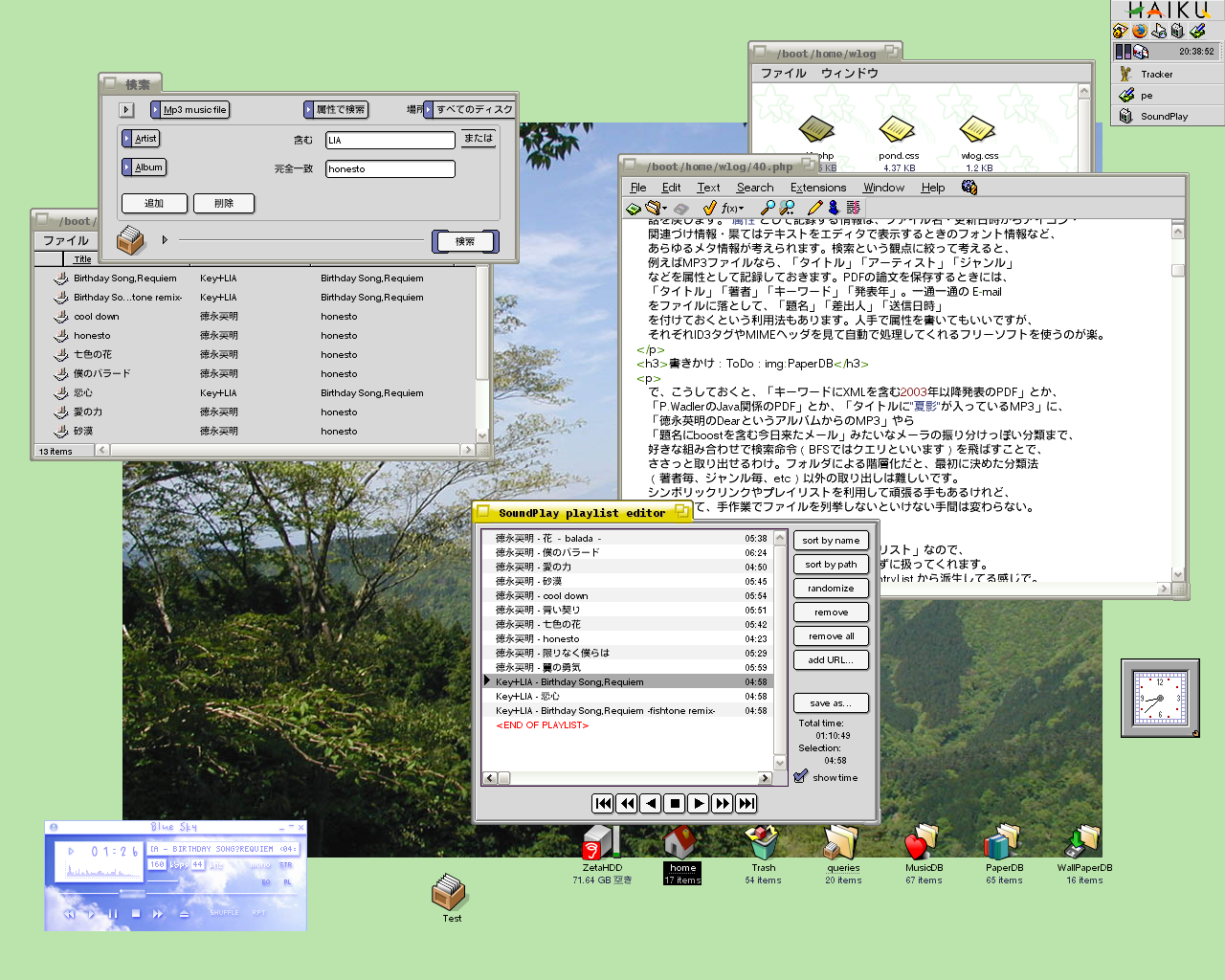
クエリを保存しておけば、Tracker (Windowsで言うExplorer)
でクエリをダブルクリックで何度でも該当ファイル一覧が見られるし、
クエリをそのままMP3プレイヤーにDrag&Dropすれば、
検索されたMP3を順に再生してくれちゃうのです。
 クエリを保存したりプレイヤーに渡したり。
クエリを保存したりプレイヤーに渡したり。
ディレクトリにファイルを入れたらディレクトリの内容が変わるのと同じで、
クエリに該当するファイルが増えたらクエリの返すファイル一覧も即座に変わります。
これを利用した
Query Watcher ていう面白い応用もあるそうです。
参考リンク
23:44 04/07/11
DEATH NOTE の2巻を買いに本屋へ。行ったんですけど、
それとは別に、店頭に並んでいた表紙に惹かれて 『残暑』 という短編集を中身も知らず買ってしまいました。
家に帰って読んでみると、最初の方の話は正直うーん?って感じ。
けど、第5話の「AとR」、第6話の「パパの歌」がいいね。特に後者。
里帰り出産てことで実家に向かう若夫婦の車の中での会話、
というのんびりとしたシーンが続いて、最後に着いた家でのんびりとした見事な結末。
この会話のテンポは巧いなあ。
追記: 見たことある絵だなーと思っていたら、『なるたる』描いた人だ。
そっちは読んだことないけど、なんだかだいぶイメージと違いますね。
世界の中心で
愛をさけぶ、を、西田氏から kinaba 氏におすすめだと (誠に勝手ながら) 思った。
と推薦されました。
あらすじを見ても特に印象に残らなかった作品なんですが、
にしだくんが何からの連想記憶で kinaba が好きそうと判断したかは想像がつくので、
あらすじで判断してはいけないのかもしれない。
題名の元ネタのSFは大好きなんで、作者の人もそのSFのファンなのだろうから、
気は合いそう。今度読んでみます。
22:43 04/07/10
私信にスレ違い、(・A・)イクナイ!! でもありがとね。>某所
しまった
希望すると caldix やら Noah
やらの載った雑誌の掲載見本誌を送っていただけることが多いので、
貧乏性の自分としては貰えるものは全部貰ってしまうわけで、
我が家にはわりとコンスタントにパソコン誌が届いています。ありがたや。
というわけで頂いた今月号のネットランナー、

…フィギュア付きだ。どーしよう、これ…って、しかも何かの手違いか、

2個来てますよ奥さん。
23:26 04/07/08
Level of Meta
「プログラムを入力/操作/出力するプログラム」 は、
「メタプログラム」と呼ばれます。OK。じゃあその、"プログラム"
って一体何でしょう? 文字列で書かれたソースコードのこと?
それとも、それをコンパイラに通した結果の実行バイナリこそがプログラム?
あるいは、コンパイラが内部で保持している抽象構文木という構造のことでしょうか?
実行バイナリをロードして実際にCPUで動いている姿こそがプログラムかもしれない。
まあ結論として、そのどれもが"プログラム"であると考えることができます。
つーわけで、同じ "メタプログラム" という言葉で呼ばれていても、
どの段階の "プログラム" に作用するのかに応じて、それは全く異なるモノになります。
- 文字列レベル
- 字句解析レベル
- 構文解析レベル
- 意味解析レベル
- 機械語レベル
- 実行時
例えばスクリプト言語で、文字列を切ったり張ったりしてから eval 関数に渡す、
なんてのは文字列レベルのメタプログラミング。
対して、C/C++ のプリプロセッサのように、字句解析の終わった後、
構文解析の前にトークン単位でプログラムをいじるのは字句レベルと言えるでしょう。
この辺の段階は、割と"なんでもあり"で無理矢理色々できちゃう代わりに、
対象プログラムのプログラムっぽい情報(この部分は変数名である、とか、
この部分はこういう型の関数を宣言している、とか)を何も扱えないので、
複雑な変換を間違えずに書くのはメチャクチャ大変。
コンパイラの構文解析段階に合わせて、構文木の変換を行うだとか、
木の生成規則を拡張したりするのが、構文解析レベルのメタプログラミング。
聞いた話では Template Haskell だとか camlp4 だとか、Scheme
のマクロだとかはこの辺りなのかなぁ、という印象。
どれもマトモに使ったこと無いので違ってたらごめんなさい。
このレベルでプログラムをいじれると、
プログラムの構造に基づいた処理(for文があったら、
その終了条件式を取り出して云々…とか)ができるので、表現力がぐんと広がります。
構文解析の次にくる段階は、意味解析。識別子 (変数名・クラス名etc)
とその宣言位置やスコープを関連づけたり、型付きの言語なら、
プログラム中の変数や式に "型" を付与するところです。
プログラムの形だけでなくて、
それぞれの式・文が何を表しているのかという意味情報まで使うのが、
意味解析レベルのメタプログラミングです。
C++のテンプレートメタプログラミングがここの代表例。
変数aの属するクラスと変数bの属するクラスが派生関係にあるなら云々…とか、
更に詳細な情報に基づいた処理が可能になります。
機械語レベル。例えば、Javaのバイトコード変換によるアスペクト指向拡張、
とかそういう話がこの段階のメタプログラミング。
ここまで来ると逆にプログラムの構造等の情報は多少落ちてしまっていますが、
「ソースコードが手に入らないプログラムに対しても処理が行える」 とか、
「元言語のコンパイラが決して使わないようなマシン命令を使って機能を実現」とか、
また色々な利点があります。
実行時。例えば実行時に動的にクラスをファイルからロードして実行とか、
実行中にその場で新しいクラスやら関数やらを作っちゃうとか、
リフレクションによって実行中のプログラム自分自身の情報を取得とか、
そういった感じのメタプログラミングもあります。
まとめ
勿論こんなにキッチリ分けられるものではなくて、
上に例として挙げたものですら、
実際には複数段階にまたがっていると言えなくもなかったりします。
そもそも上のような区別が意味をなさない言語も多々ありますし。
まあ、いろいろあるよ、ということで。
Ocaml-templates
MLスレ
を見たら Ocaml-templates という面白げなものが紹介されてました。
型宣言と同時に、その型に適用したい"テンプレート"を指定できて、
そうするとテンプレートをその型でインスタンス化してくれる、というシステムかな?
CRTPっぽい。テンプレートは型情報を扱えるメタ言語で記述できるらしい。
17:27 04/07/06
ハードディスクがトンだー!!
・・・というわけでいつもと違うマシンから更新。再インストール面倒だ。
ICPCの結果が出てました。毎年同じ事を言ってる気がしますけど、
チームメイトの二人はすげぇなあ、と今年も感心。
私が一人でマシュマロをぱくぱく食べてる間に難しいのを両方解かれてしまいました。
今年が最後なんで、アジア予選ではいい順位出したいところです。頑張ろう。
00:54 04/07/04
白蛇島クリアー!!(挨拶)
ACM/ICPC
7/2の夕方に、ICPC
というプログラミングコンテストの大会の予選に参加してました。
去年『Gokuri』って名前のチームを組んだのと同じ面々で、
今年はチーム名『Gokuri-Squeeze』です。由来は推して知るべし。
予選結果は月曜日に出るらしいので発表待ちです。
出された問題は
このページ で公開されてます。
3時間以内にできるだけ多く、速く、ミス少なく解いた方が勝ちというルール。
暇つぶしに挑戦してみると面白いかも。
00:37 04/07/01
『新書マップ』
… テーマで探す新書ガイド、ということで、キーワードで検索をかけると、
関連しそうな分野の新書一覧をピックアップしてくれるサービスだそうな。
キーワード欄には適当な文章を突っ込むこともできて、例えばこの
w.l.o.g. の一個下の記事を使って検索すると、
[日本人と英語][翻訳][英語公用語論][言葉と日本人][通訳]
なんていう分野と新書の情報が表示されます。
んで更に、検索結果から何個か分野をチェックで選んで再検索すると、
その分野(群)をキーに、
それと近い/関連した分野と新書を引っ張ってきたり。
その "再検索" をすると高いランクのところに元の分野と近いのが色々出てくるのは、
まあ当たり前なんですが、ヒット順位の低い、"関連は…あるのかなぁ?"
くらいの微妙な位置のジャンルを次々と横道にそれる感覚で渡り歩くのが、
意外と面白かったりします。
[インターネット] → [新宗教と新新宗教] → [デカルト] → [言語学の巨星]
→ [バイリンガリズム+哲学入門] → [幼児教育] → …
と、まあ
他人事のように紹介しようと思ったんだけど。
ちょびっとだけ関わらせてもらったプロジェクトなのでうまくいくといいですねぇ。
16:44 04/06/26
reset てユニットの 『station』 ていう曲が素敵。
インクリメンタル翻訳
D言語のリファレンス
の 日本語訳 は、オリジナル文書が
2~3週間毎に更新されるので訳もそのたびに書き換えています。
変更箇所を見落としなく目で探すのは不可能に近いので、当然ながら
diff
を使って英語版の古いヤツと最新のヤツの違いを機械的に列挙するわけです。
で、そのdiffさんが親切に「aaa 行目から bbb
行目の間はこれこれこーいう行が新しく挿入されてますよ」
などと変更箇所を並べてくれるので、それを見ながら日本語訳を直していきます。
ところが、ここで問題発生。英語版でaaa行目って言われても、
いざ修正を加えたい日本語版でそれが何行目なのかが正確にわからないのです。
英語と日本語でそんなに行数が変わることはないので aaa
行目よりも少し前を探してみれば見つかるんですが、これは意外と面倒。
要は、考えてみれば当たり前なんですが、最初から、すべての段落すべての HTML
タグの行数を変えないように翻訳しておけばよかったんですよね。
始めに勢いで訳を開始したときに全くこの問題に気づかなかったので、
後で大変なことになりました。
…以上、先週ようやく行番号を揃え直し終わった感想。
もっとうまいやり方があるのかなぁ。
10:22 04/06/21
Haiku OS !
OpenBeOS プロジェクトの正式な名前が「俳句」に決まったそうです。
ロゴいいなぁ。格好いい。BeOS R4.5 (だったっけ?)のコードネームが
「Genki / 元気」で好評だったので、その流れで和風名が来た感じでしょうか。
PTAPG
"Parsing Techniques - A Practical Guide" という本がありまして、名の通り、
構文解析プログラムの理論と実装に関する技術が細かく解説されています。
チョムスキーの言語階層の話から、下降型・上昇型パーザの一般的な話、
正規表現をDFAに変換して正規言語をバックトラックなしで処理したり、
先読み表を作ってLL(k)/LR(k)言語をバックトラックなしで処理したり、
変な入力を喰わせられたときのエラー処理の方法を述べてみたり。
構文解析って言うとコンパイラの本の最初の方で部分的に扱われるのが常で、
徹底的にそれにテーマを絞ったテキストってなかなか珍しかったりもします。
PDFで全文公開されてるので興味のある方は是非読んでみてください。オススメ。
今出版されている版は上に書いたようにかなりスタンダードな内容なんですが、
久々にページを見てみると、なんと June 15, 2005
に大量に項目を追加して第二版が出るらしい。新しい内容も
generalized deterministic parsers や linear-time substring parsing
と、自分にほとんど知識がない技術なので期待大。
また最近
リンクして終わり日記になってるので要反省。
- 海の上の少女 ( L'Enfant de la haute mer )
05:33 04/06/13
結城さんの日記にて
バランス人名クイズ
という面白そうな話題。ホフスタッターとスマリヤンしか知らなかった…むむむ。
と、それはともかく、この10人という人数は、
増やしたり減らしたりするとゲーム性はどう変わるだろう?
1人…ではゲームが成立しない。2人では大変に難しい問題になる。
「回答者は皆、AさんとBさんのどちらか一方は知っているが、両方知ってる人はいない」
という完全にかけ離れた有名人AさんとBさんを探さないといけない。
で、3人、4人…と増やしていくと、だんだん簡単になっていく。
逆に増やす方を考えてみる。例えば500人を挙げなきゃいけないとしてみよう。
これはこれで難しそうだ。回答者の人数に強く依存するけれど、
うっかり"誰でも知ってる有名人"や、"誰も知らない無名人"
を挙げてしまう危険が10人の場合と比べて高くなっているように思われる。
つまり、減らしすぎても増やしすぎても難しくなるわけで、
どこかに「バランス人数」が存在するのだなぁ。
00:58 04/06/10
トップのカウンタが2000000を越えていることに気づきました。
あと、思い返してみれば、多分明日がほーむぺーじ開設5周年だ。
いつも皆様ご来訪ありがとうございます。
最近ほんと何も更新してなくてスミマセン。
23:05 04/06/08
最近注目しているテキストエディタが2つあって、
『萌ディタ』 と、
『Alpha』 です。どちらもまだまだ発展していく途上ですが、
Unicode の細かい仕様の実装をはじめとして次々と作り込みが進んでいて、
将来的には物凄い完成度に到達しそうな予感がします。
あと、どちらのエディタも作者さんによる開発日記/開発メモがWeb上につけられていて、
技術的な面でメチャメチャ勉強になるという共通点も。
なお、以上の話はピーステーブル云々とは全く関係ないです。
edi
ついでだからエディタの話続き。テキストエディタを作る上にあたっては
バッファ構造の他にも色々と解決すべき問題はありまして、
どのくらいマジメに字句解析してキーワード色分けをするかとか、
改行文字をまたいだ範囲に正規表現検索でマッチさせたい場合面倒だなぁとか、
文字の横幅が一定でないので横の位置の計算が簡単ではないとか、
世界中の色んな言語・文字種・キーボード配列などなどに対応しようと思うと、
正しく実装できたかの検証が大変だとか、例えばそういう話です。
なかなかチャレンジングで面白そうだ、と思った方は、
既存のエディットコントロールを使わないエディタを一つ書いてみると
きっと楽しいですヨ。ちなみにGreenPadは上記の問題のどれ一つとして
完全には解決できていないので、偉そうなことは言える立場に無いのですけど。うへ。
なんとなくリンク
Compiler Tools という、イギリスの大学の講義ページっぽいところが、
エディタのSyntax Highlightingについては詳しいです。
コンパイラの授業の一角のようだけれど、こんな周辺まで扱っているのは凄いなぁ。
エディタの色分け処理って言うのは確かにコンパイラの第一段階である
"字句解析" と行う作業は同じなんだけれど、
ユーザの入力に応じて解析対象のデータが変化するので、
幾らかの考慮が必要になるわけです。
そのページ曰く、Ostermiller
というとこが出してるJavaによる構文色分け用のライブラリが良いらしい。
22:38 04/06/07
なんか来た

責任者は至急これの取り扱いを決定すると良いです。
ICFP
まともなのが書けなかったのでsubmitしませんでした。来年頑張る。
ギャップバッファ revisited
応用編/発展編。
Sticky
ギャップバッファを実装に使っているテキストエディタとして有名なものは、
GNU Emacs と、JavaのSwingのエディットコントロールがあります。
こいつらは、文書全体を一つの大きなギャップバッファで管理しているそうな。
で、バッファ中の"位置"を表すデータのリストを別に管理することで、
例えば"行"の一覧を保持して、描画等に使っています。
しかしその時、文字を挿入したときのデータの更新コストはどうなるでしょう?
ギャップバッファへの文字の挿入処理は、前に見たように、非常に効率的です。
問題は、"行" の位置を保持している変数を更新する手間はどうか、という点。
Vectorを使っていると、挿入位置より後にある"行"を表す変数は、
全て更新(+1)しないといけません。挿入すると、
以降の文字列が全部後ろにずれてしまいます。逆に、LinkedList
を使っていれば、全く更新の必要はありません。どこかで挿入があっても、
LinkedListの他の部分はまったく更新されませんでしたから。
ギャップバッファの場合は、やはり、実にギャップバッファ的な特性になります。
つまり、同じ位置への連続挿入の時は"行"を表す変数の変更は全く不要です。
直前の挿入位置と離れた位置へ挿入するときは、その二つの位置の間を指していた
"位置変数"についてのみ更新が必要になります。
こんな感じっちゅーか、↓こんな感じ。
class GapBuffer {
class Marker {
int physical_index;
public char getPointedChar() { return buffer[physical_index]; }
}
private char[] buffer;
private Marker[] sorted_list_of_markers_created_from_this_gapbuf;
private void moveGap(int i) {
// 1:バッファ中のギャップ位置を動かす処理
// 2:sorted_list_of_markers_created_from_this_gapbufのうち、
// ギャップ移動範囲にあったヤツのphysical_indexを修正して回る処理
}
public Marker GetMarker(int logical_index) { ... }
...
}
このMarkerは単純な一画面エディタの行情報の保持以外にも使えます。
複数のViewが異なる行開始位置を持つときでも各々別の Marker
リストを持たすだけで済みますし、そもそも行以外でも、
テキストデータ中の特定の位置を指し続ける 「Stickyな」
ポインタの実現に便利です。
多くのエディタでF2キーに割り当てられてることが多い、
[ブックマーク]とか[しおり]とか呼ばれている位置を記憶する機能ですね。
他には統合開発環境で、ブレークポイントの位置を記憶とか。
行頭という"位置"だけを別扱いして管理するエディタだと、
このような機能を効率よく実現するのはなかなか大変です。
あと余談ですが、このサンプルの ..._created_from_this_gapbuf
のようなのが、boost::weak_ptr や、他の言語にもありますがいわゆる「弱参照」
を使う典型的場面です。
boost::shared_ptrや普通にガベコレ管理のポインタにしてしまうと、
Marker が全然解放されなくなっちゃうのがおわかりいただけるかと。
deque
更に、ギャップバッファの下位バッファを単純なVectorではなくて、
チャンク分けして管理する方法があります。えーと、
こちらの解説が秀逸です。STLで言うと、vector を deque
にしたようなメリットとデメリットが得られます。(だんだんいい加減になってきた)
Circular
ギャップバッファの最悪パターンっていうのは、
先頭付近で編集があった直後に末尾付近で編集、っていう、
ギャップがバッファの端から端まで移動しなけりゃいけない時です。
この最悪移動距離をせめて半分にしようということで、
下位バッファにVectorでなく環状バッファ
(先頭と末尾が仮想的につながってるVector)を使う提案が
Flexichain (PDF) というライブラリでなされています。
速くなるのかな?
PieceTable
PieceTableの表の管理に更にRopeやPieceTableを使うのに効果があるのか疑問、
みたいなことを前回書きましたが、
よく考えたらあの表は他と共有する必要がないわけで、
Immutable性さえ外せば一カ所書き換えも高速に実現できて問題なさそうです。
木構造にすればPieceTableは速くなるんじゃね?という提案。
あと、Vim や Gtk のテキストバッファは実際に木構造っぽいものを使っているらしいですよ。
その他リンク
Swingのテキスト関係のコンポーネントについての
The Swing Text Package っていう文書群が、バッファの構造に限らず、
エディタを作る上でメチャメチャ参考になるのでオススメです。