Derive Your Dreams
16:48 06/10/31
無限ループ
From このへん。
_=*"".."_"
0H10B、とかはありでしょうか。このRangeのmin辺りを呼べばメモリも食わず経済的です。
ゴミメール
す 写 つ 男 当 ご 景 行 わ こ 先 秋
女 ぐ 真 ま 性 サ 希 気 き た の 日 も
性 に 付 り 会 | 望 も 違 く 度 小 一
h の ご き 本 員 ク も 徐 い し ア 池 段
t 写 希 プ 当 様 ル 充 々 で 山 ド よ と
(以下略)
なんか縦書きのスパムが来ててちょっと面白かったです。フィルタ避けでしょうか。
でもURLまで縦書きだと、さすがに誰もたどろうとしないと思うんだ。
クリックは当然のこと、コピペもできない。
ゴルフ
ネタバレはないですよ。
Switchboard:
109B (Ruby, とりあえず書いてスペース削っただけ版)
→ 88B~74B (Perl, いかに2本入れ替えと3本入れ替えのコードを共通化するか試行錯誤)
→ 74B (Ruby, substrとか長いよ!と思ってRubyに転向したら完全に同じバイト数だった)
→ 73B (凡ミス除去)
→ 72B (長くなると予想して一度捨てたアルゴリズムで書いてみたら短かった)
→ 71B (私はRubyについて知らなすぎでした凡ミス除去)
Total-Triangle:
71B (Ruby, とりあえず書いたらこんなん出ました。
短いコード、と考えずに速いコードを考えた方が近道なのかも。)
→ 65B (あとは小技を幾つか)
Home On The Range:
203B~184B (PHP, とりあえず解いた)
→ 67B (Perl, s///すげー)
→ 60B (この正規表現で行ける!と閃くのに全Golf中で一番頭を使いました。すげー)
→ 57B (もいっちょ)
→ 55B (※追記:この日記書いた直後に閃いた!つーかなんでこれ
60B の時点で思いつかなかった俺)
Prime Factors:
153B~106B (PHP, アルゴリズムはごく普通。ひたすら小技を駆使)
→ 89B~83B (Perl, 言語変えただけ)
他にPascalとVigenereとPiとDiamondsとLifegameも頑張ってるのですが、
上に追いつける気が全然しないですね。みんなすごい。特に Vigenere Cipher が
全くの謎。
10:38 06/10/22
Songbird
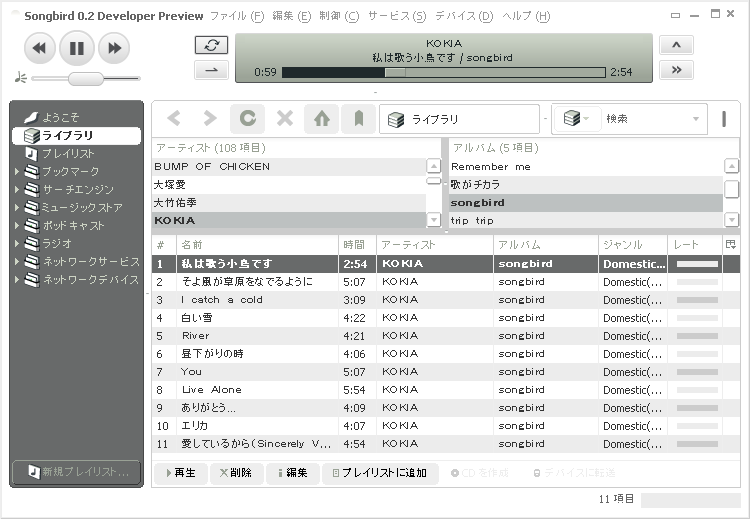 Songbird というプレイヤーの 紹介記事 を読んで、気になったので入れてみました。Songbird で Songbird を
流してみたかっただけともいいます。デフォルトで用意されているスキン
(正しくはスキンではなく "Feather" と呼ぶらしいです)が自分の好みにあってて
いい感じです。
Songbird というプレイヤーの 紹介記事 を読んで、気になったので入れてみました。Songbird で Songbird を
流してみたかっただけともいいます。デフォルトで用意されているスキン
(正しくはスキンではなく "Feather" と呼ぶらしいです)が自分の好みにあってて
いい感じです。
ただ、まだPreview版ということもあってか、うちの環境だと結構ガンガン
強制終了してしまいます。今後に期待。
Random
2個下のランダム生成の話について。
Gus さんから、答えが偏らないように連結グラフをランダム生成する
工夫を紹介していただきました(私が下であげた方法だとわりと密集したグラフに
偏って生成されてしまいます)。ありがとうございます。
smoking186 さんからは "A Personal View of Average-Case Complexity"
という論文が近いかも、という情報などなど。これは読まねば。
まだ中身全然読んでないんですけど
Despite the above work, I feel the structure of average-case complexity has
not received the attention due to a central problem in complexity theory.
The goal of this paper is to motivate more research in this area, and to make
the research frontier more accessible to people starting work in this area.
マイナーだけど面白い話があるからちょっくら布教するぜ(意訳)!
という愛が伝わってきて楽しげです。
02:30 06/10/21
○○度チェックとか
占いとかは逆向きに使うといいらしいので。
shinh 度チェック
を使って、shinh な人におすすめのプログラミング言語を判定します。
選択肢はこれ。
結果発表~! おすすめ度が高い方から順に…
D 108, Cecil 104, Merd 102, Claire 99, Erlang 98, Brainfuck 98, ECMAScript 95,
Icon 90, TyRuBa 89, gbeta 88 …でした!ちょっと普通に D が一番上になってしまって
オチがつけにくいのですが。多分「SDL」が致命傷でした。あーあとgbetaの記事を
再開しないと…と2ヶ月に一回くらい定期的に思っています。
Icon といえば
Snobol や Icon の生みの親である Ralph Griswold 氏が亡くなったと
LtU で知りました。
Icon について上の記事を書いた当時は周辺知識もないまったくわからん状態で
手探りでいたわけですが、今の目で言語のリファレンスを見直してみたりすると、
だいぶ違った印象で見えてきますね。勉強し直したほうがよいかもしれない。
…と多分これから2ヶ月に一回くらい定期的に思い続けそうな気がします。
あ、Icon に関しては
Matz さんによる紹介
がとてもわかりやすくてお勧めです。
23:51 06/10/19
ランダム生成
関数の自動テストをするとき...というかつまり、UVA とか PKU の Online Judge に載ってるような
感じの問題を作ったときに、撃墜用データセットの一部として使うために "事前条件を満たす
ランダムデータ" が欲しくなることがあります。
例1
たとえば 「連結グラフとその上の頂点が1つ指定されたときに、そこからグラフ上で一番遠い地点を
計算せよ」
という問題を作ったとすると、ランダムデータとして、ランダムに
"連結な" グラフを生成しないといけません。取れる手段は幾つかあって、
- 完全にランダムにグラフを作ってみて連結かどうかチェック
→ ダメなものは破棄、を繰り返す
- 連結なグラフだけを生成するようなうまいランダム生成方法を使う
一個目の方法で十分な場合はそれでいいのですが…チェックして破棄という方法では、
条件を満たすデータの割合が低すぎる場合は効率が悪い。連結性くらいなら効率は
大丈夫ですけれど、そもそもそれ以前に、「グラフが連結かどうか」を判定すること自体、
そこまで自明な問題ではありません。テストルーチンの中身が、テスト対象と同程度…と
まではいかなくても複雑になってしまうのは、ちょっと本末転倒な気がしてしまいます。
この場合は二番目の方法がうまくいきます。点1個のグラフから始めて、
それまでに入れた点のどれかとは必ず繋がるように次々点を加えて行けばOK。
from random import *
頂点数 = randint(1, MAX)
無向グラフ = [[]]
for n in range(1, 頂点数):
無向グラフ.append( sample(range(n), randint(1, n)) )
こんな感じで。いやこれだと確率分布は偏りますが、考えるのが面倒になったので
これでいいことにします(適当)。「必ず連結なグラフしか作らない」し、
「連結なグラフは必ずこれで作られうる」ので。
例2
「xy平面上に、円が1000万個ほど重ならないようにばらまかれています。
一番近い円はどれとどれでしょう。」
という問題に必要なのは、
「重ならない1000万個の円」というランダムデータです。ちなみに1000万個というのは、
二重ループで一番近い組を探そうとすると日が暮れるサイズです。
「ランダムに1000万個の円を作ってみて、重なってないことをチェック」するのは、
今回もやはり苦しい。繰り返しますが、二重ループで全組み合わせが重なっていないことを
確かめるのは現実的ではありません。なんかもっと賢くやらないといけないのです。
のですが、たぶん私が思うに、重なってないことのチェックを賢くやるのは、一番近い
ペアを探すのと本質的に同じレベルの複雑さです。なにか違うような気がする。
「重ならない円だけを作るうまいランダム生成」 も、今回はなかなか思いつきません。
いえ、「絶対重ならない」だけでよければ幾らでも作れるんですよ。
// 中心座標 (x,y), 半径r の円
x = ランダムな整数
y = ランダムな整数
r = 0 より大きくて 0.5 より小さいランダムな実数
とかで円を作れば、中心が一致しないかぎり重ならないのです。
で、中心がかぶってないことはHashSetなどに突っ込んでおけば簡単にチェックできます。
でも、このアルゴリズムで生成されうる円集合は、あきらかに偏ってます。作為的です。
もしかしたら、"こういう方法でばらかまれた円ならたまたま一番近いペアを見つけられるけど、
もっと一般的なデータを喰わせるとバグが露見する" ようなコードがテストをPassしてしまう
かもしれません。手で作るテストケースと比較してのランダムテストの利点は、
プログラマの想定外のデータが「偶然」試されてくれることですが、
ランダムデータ自体にプログラマの手が入ってデータ空間が制限されていては、この利点が
薄まってしまいます。
結論
結論…は実はなにもなくて、こういう場合ってどうすればいいのかなあ、とつぶやいて
みたかっただけなのでした。"条件を満たすランダムデータ" が欲しいっていう状況は
そこまで特殊ではないと思うので、どこかのどなたかが色々考察してそうな気はするのですが。
条件を満たすことのチェック問題と満たすデータのランダム生成問題の間には、
計算量理論的にはどういう関係があるのかとか。
もっとも「Online Judge に載ってるような感じの問題を作ったときの撃墜セット」という前提は
多分特殊かもしれなくて。そもそもこの前提条件の下では、正解プログラムが
同時に存在していなければいけないので、テスト対象と同程度に複雑なテストルーチン
を恐れる必要はそこまでないかも、とか。あるいはテスト手法のひとつとしての
ランダムテスト
であれば1000万個のデータをぶち込む必要はなくて、もっと小さいデータを使えばよいので、
それこそ二重ループ等の遅いけど確実なチェックルーチンを使えばよろしかったり。
テスト以外の用途なら "ランダムっぽいデータ" があれば十分で、生成されうる集合が
実は偏ってることが問題とならないこともあったり、などなど。
23:31 06/10/13
なにもない
Linez にハマったり、相変わらず CodeGolf
ったりしています。ちなみに結局 Ruby と Perl の使い分けに落ち着いてしまいました。
なんか長くなりそうな問題は避けてひたすら短いのばかり弄ってる根性無しです。
a=[0] の代わりに *a=0 !とか s/…/…/eg
は凄いなあ、とかそんな日々であります。
今までまったく読めなかった暗黙の $_ を使った Perl
コードが読めるようになってしまった…。
あと『はこぶね白書』
が2巻になって面白くなってきた感じがするよ。
12:07 06/10/06
ゴルフ
shinh さん
お勧めの Code Golf に挑戦してます。最近覚えた
Python を使おうか日頃から使い慣れてる PHP を使おうか、それともshort codeには
向いてそうな Perl や Ruby で頑張ってみるかしばし迷った末、とりあえず PHP で突撃。
かの有名なAudreyタンも "What has absolutely nothing in common with Haskell"
と褒めておられることですし。
で、ちょこちょこ解いてみたんですがどれもこれも上位ランカーのスコアが
凄すぎて困る。それなりに頑張って最適化してみたつもりの99 bottles of beerで、
自分:207B、PHPトップ:181B、総合トップ:176Bとか。これはやりがいがあります。
というか、何か根本的に発想を変えなければいけないよーな気がする。pack/unpack
なんだろうか。
以下、たぶん知らない方が幸せだった知識。
- 最後の ?> は省略してもセーフ。
- ?> の直前だけは 行末セミコロン; は不要。
- printは式の中で使える(値は通常はtrue)。echoは使えない。あとprintは1引数。
- 演算子の優先順位だけでなくて、左辺値として妥当か判定までしてparseしてくれる。
つまり
$x+($y=$z) は $x+$y=$z と書ける。
- 未定義定数は(怒られるけど)その定数名の文字列扱い。
23:26 06/10/04
Dragon
今日やっと
『Compilers』
が届きました。今6章の途中あたりを読んでます。なかなか第二版で加筆された章まで
たどりつけない…。あと、今Amazonを見たら自分が買ったときより4000円くらい安くなってる
気がしないでもないですが気にしない。
とりあえず、サンプルのコンパイラ(のFrontEnd)がJavaで実装されているのが
今風だなあ、という感想です。たとえば記号表の実装詳細が
Hashtable~!! の一発で済んでいるのは素晴らしいと思う。
文字列を hash する良いアルゴリズムに関する知識はもちろん重要ですが、それはたぶん
コンパイラの本質ではないですし、いまどきの言語の標準ライブラリには十分良い
hash 関数がありますし。その分コンパイラのコンパイラたる部分に記述が注力されてるのは
嬉しいところです。
BrainScan
ということで、新しい検査式を導入してみました。
BrainScan再び
うわわわわ。ありがとうございます!
00:28 06/10/04
ドンラーポ
GikoForthなどなどのForth方言の中の人ことNo22氏の、
「それは逆ポーランドじゃない」 という一連のエントリがとても面白いです。
式 3*(2+1) の代わりに 1 2 + 3 * と、演算対象の後ろに
演算子を持ってくる表記法が逆ポーランド記法。Forth のような「スタック族」の言語では、
まさにそのような形で式が記述され…されているように見えます。けれども、Forth
の言葉は実は逆ポーランド記法ではないのだ、というおはなし。
モデル検査
Edmund Clarke 先生 の講演を聴いてきました。
モデル検査の偉い人です。
演題は、"From Hardware to Software and Back Again" で…
最初にモデル検査がブレイクしたのはハードウェア検証の分野で、それをさてソフトウェアにも
応用しようということになって、色々な技術が開発された。しかし、
ソフトウェア全般の汎用的なモデル検査というのはなかなか難しい。ヒープがあって
ポインタがあって再帰があって状態空間が酷いことになって、なかなか難しい。
そこで再びハードウェアの世界に目を移してみると、Verilog や VHDL や SystemC のような
高級言語で、まるでソフトウェア記述に使うような複雑な言語で、ハードウェアが
設計されるようになってきている。ソフトウェアのモデル検査のために培われた技術を、
ここに逆投入すると効果的なのではないだろうか? ポインタとか再帰とかないから楽だし。
…といった流れでした。流れはともかく、中身は普通にかなりわかりやすい(時相論理による)
モデル検査の入門として聴けました。このあと筑波大や産総研でも講演されるそうなので、
興味のある方はぜひぜひ。
モデル検査といえば、yoriyukiさんの
BrainF*ckのモデル検査器
が、何をやっとるんだこの人は(ほめ言葉)という感じで非常に楽しいです。
しかし bf を書いているとわりと真剣に「コード上の指定した位置で常に *(ptr+1)==0 で
あること」や「実行終了時にポインタが初期位置に戻っていること」辺りの性質を保証
したくなるので、チェッカーがあると嬉しいかもしれない。わりと真剣に bf
を書いていることが第一の間違いですが。
しかし
最近他の人のエントリが面白いですよーという紹介ばっかりで我ながらアレだ。
