Derive Your Dreams
17:24 06/09/27
XP theme
昨日 OSXP というビジュアルスタイルを知りました。
完全にMacOS化してない辺りがかなり好みです。しばらく使ってみよう。
ただ日本語のせいかスタートメニュー周りがずれるので、TClockで調整したりユーザーの
表示名をスタイルに合わせて変えたりと適当に酷い合わせ方をしてます。
マジメに直そうよ>自分。
LCSD
LCSD '06
(Library-Centric Software Design) のプログラムが出てました。
"ライブラリ" そのものを対象にしてその設計や実装について議論する学会…ということで
特に言語について限定されてはいません。が、実際中身を覗いてみると、
基調講演や Program commitee の面々の名前を見る人が見ればすぐわかるように、
えらく濃いC++使いが集結する感じの学会です。
(や、必ずしも皆が皆C++人というわけでもありませんが…。)
興味をひかれたタイトルは
"A static analysis for the Strong Exception-Safety Guarantee"
と
"Extending Type Systems in a Library"
あたりですかね。
14:33 06/09/21
ICFP
で、学会の方の感想です。
ML界はModuleが流行りでHaskell界はGADTが流行なのかな的イメージ。
1日目
まずは、高速な商用Scheme処理系として有名な Chez Scheme の中の人による
招待講演で幕が開きました。個人的にはこれが一番楽しかったというか、とったメモを
読み返したら半分がこの話の時のメモでびっくりというか、要は最初のセッションまでしか
集中力が持ってないだけですね。Chez Scheme の開発の歴史を振り返りながら、
高速化のために入れたHackや設計上の選択について小話を色々、という形式のスピーチでした。
- 実際にprintされるまでは名前文字列を作らないように遅延させると
gensym が25倍高速化。
- 継続やClosureを取る際には、
スタックを単純コピーすると書き換わる変数の共有ができないので、
関数フレームもすべてヒープに置いてGCに任せる…というのがよくあるアプローチ。
だが、これは遅い。(例えmallocがスタックポインタの加算と同じ程度に速くとも、
ポインタのチェインを作る手間の分遅い。)むしろ、set!
され得る変数だけを特別にスタック上にはポインタで保持することで、
スタック単純コピーで済むようにした。
- 関数とその他の名前空間が分かれてるLispだと、関数じゃない値を call
したときのエラートラップが簡単なのだけど、Scheme はそうなっていない。
でも、名前空間が分かれてる場合の手法を応用できた。
- Don't forget about machine generated codes.
- Must not accept partially correct solutions.
などなど。
"Delimited Dynamic Binding"
。動的スコープなストレージと
部分継続は、何も考えずに両方合わせて使うと妙な動作になってしまう。
それをきちんと組み合わせるにはどうするか、という話。
本質的には、両者の使うスタックを適切にマージしてやればよいということだと
理解したのですが違うかも。部分継続はよいとして、動的スコープが嬉しい場面と
いうのにあまり遭遇したことがないので、利点が実感できてない感があります。
Spiritのヤツ はtupleを使って静的スコープで再設計できそうな使い方しか
してないしなあ。
"Static Typeing for a Faulty Lambda Calculus"
。計算機に乗っている値は、
どれだけ頑張っても、例えば宇宙線が
飛んできたりして不可避的に値がバグる可能性がある。さて、計算途中で多少値が
ランダムに変化してしまっても最終結果には影響が及ばないような計算モデルを
考えることはできるだろうか、という話題。あくまで "Baby Step" ですが…として
発表で提案されたのは、Lambda-zap という、単純型付きλ計算に多重化+多数決の
仕組みを入れてちゃんと多重化されていることを型で保証するとかいうシステムでした。
多数決プリミティブの動作が宇宙線でバグったらどうするんですかーやら、
そもそもデータではなく命令ポインタがどっかに飛んだらーとか、いろいろ
つっこまれてました。面白そうですが大変そうです。
"From Structures and Functors to Modules and Units"
。
モジュール間のinternal link(モジュールが明示的にリンクするモジュールを指定してリンク
するタイプ。JavaのimportやらMLのstructureやら)とexternal link(外からモジュール同士を
接続の仕方を指定して繋げるタイプMLのfunctorやら、Cのexternとオブジェクトファイル
みたいなもの)という二つの概念をきっちり整理し直すと、再帰functorに当たるものなどが
使える表現力豊かなUnitというモジュールシステムが作れますよーという話、だったような
気がする。正直さっぱりわかりませんでした。
「Scala のモジュールシステムと関連が深いんじゃ
ないでしょうか?」との質問が出たりしていたので、今度Scalaを調べてみようか、
と思い始めました。あと
Double Vision Problem という、再帰モジュールの理論に関して重要とされる
テーマがあるらしいことを知りました。
この日は他には、GADTの型推論のやり方の話や、また別の再帰モジュールの話などなど。
Schemeのマクロでただ構文木を書き換えるんじゃなくてrewrite以外のこともできる
オブジェクトを木ノードとして生成する形にすると静的解析を組み合わせるときに便利、
という話もありました。
2日目
招待講演は、並行プログラミングに関する証明を行うための Rely-Guarantee Method
という手法についてでした。
"Transactional Events"
は個人的に興味があったのは実装のしかたなのですが、
STM使います終わり、だったのでそれはまあ何とでもなるよなあ…と。
"Modular Development of Certified Program Verifiers with a Proof Assistant"
は Tossy-2氏 の修論方面の話なのかなーと
いうイメージだけ抱きましたが、よくわかってません。
"Equality of Streams is a Pi^0_2-Complete Problem"
。
「普通にHaskellでやるような感じの等式系で定義された遅延無限リスト2つが等しいかどうか?
を判定する問題」は、全然どうしようもなく解けない難しさです、という証明。
「一般には無理なのはわかったけれど、同値性が判定できるような、ある種 "筋の良い"
無限リストのみに制限して定義できるようなシステムは考えられるのか?」 という質問が
出て、何かしらありそうだがはっきりしたことはまだ不明、という答えでした。
昨日の酒井さんの記事を読んで、その文脈で何か面白い特徴付けになってたり
しないかなーとさらに安直な思いつき。
"OCaml+XDuce"
はOCamlにXMLリテラルと、XMLのスキーマを言語の型として取り込む
正規表現型というのを突っ込む話。OCamlの型とは結構異なる型システムを混ぜることに
なるので、無理に合体させようとせずに、2種類の型システムがうまく共存するような方法を
目指した、というアプローチが面白いです。理論的にはXMLに限らず、データの種類を
限定すると汎用の型ではなくそのデータに特化した旨い型システムが導入できることがあるので、
そういう「外部の型システム」をOCamlに取り込むための理論として作ってあるらしいです。
3日目
韓国の人と食事しながら話していて、ソウル大では
nML というML方言が授業で使われてる、
という話を聞き込んできました。面白そうなので調べてみたいけど言語仕様書が
韓国語オンリーだ。うーむ。
招待講演は「Functional Pearl に載る秘訣」。Functional Pearl というのは、
ジャーナル『Journal of Functional Programming』 のコラムで、関数型言語における
いろんな新しいイディオムや技法が紹介されるコーナーです。
前にここで紹介した Zipper
が例えばFunctional Pearlの代表例ですね。他にも
検索する
とザクザク引っ掛かります。
この日は昼食前のセッションは他のことをしていて、午後は眠気Maxだったのでほとんど
の発表は記憶の彼方であります。唯一まともに聞いてたのが
"Programming Monads Operationally with Unimo"
で、これは非常に楽しかったです。
Monad を楽に定義できるようにする補助ライブラリ Unimo というのを作ったというお話。
標準的な return と >>= によってMonadを定義するという方法は、どちらかというと
"Denotational な" 方法と言えます。つまり、必ずある定数を返す計算とは具体的にどういう計算なのかをreturnとして定義して、ある計算とある計算を
繋げた計算とは具体的にどういう計算なのか、を >>= で定義するわけです。
これに対して、"Operational な" 方法とは、いったん、計算を表す代数的データを構築して、
その計算を実際に動かすインタプリタを書く形式でMonadを定義する手法。
Unit演算とBind演算の組み合わせをinterpretする場合の規則はライブラリ側で自動で
与えてしまうことにすれば、対応するモナド則が半自動的に満たされたりする。
MonadとMonad Transformerの実装で、計算を表す代数的データの部分は共有できたりする。
…という。
00:16 06/09/21
ICFP Programming Contest
最終結果が出ています。
サイトにはまだ出てないかなーですが今年の言語は
2D is the programming language of choice for discriminative hackers!
いやまったく。くあー。やられた。
"RML is a fine programming tool for many applications!"
ってことにすればよかった。今は反省している。マジレス禁止。
その2Dで20点差を付けられるとは思わなかったのだけど
なんか秘技があるんですか、とSmartassの人に聞いてみたら「手で超頑張った」
とのことでした。ちなみにUMの実装は最初C++で後でCに換えたらしいです。
あらためてご紹介
さて、最近 Haskell やら OCaml やらで人気の「関数型言語」に関する世界一の学会として、
ICFP (International Conference of Functional Programming) というのがあります。
今年の学会の内容については別の記事でそのうち書こうかと思っていますが、それはともかく、
そのICFPが主催するプログラミングコンテストがありまして、それが ICFP Programming
Contest です。毎年学会の2ヶ月くらい前に開催されてます。
今年のコンテストについての感想は参戦した直後に書いたのでそちらを参照して下さい。一言で言うと、
とても楽しかったです。コンテスト終了後も挑戦したい人がいつでも挑戦できるように
問題セットは公開されていますので、まだの方は是非是非
ご挑戦を。おすすめです。
で
言わば「メイキング・オブ・ICFPコンテスト」の
スピーチが学会での結果発表と同時にありまして、自分が「楽しい」と感じた理由を
ちゃんと狙って作っていたんだなあと思って改めて楽しくなったので、
ここに引用しまくります。
Fun first.
The contest should be fun for participants and, hopefully, for the organizers
as well. The contest is ultimately a diversion; its success should be judged
like ay other game or pastime. The majority of entrants should make
substantal progress, and problems should be interesting, not tadeous.
とか、まあ↑は置いておくとしても、特に
Community Service. ...(略)...
The contest draws significant attention from outside the functional programming
community. Consequently, it should make use of the opportunity to advertise
the ideas and techniques developed by programming languages research.
There are a plethora of interesting problems in our field,
and the contest tasks should draw from them.
ですね。関数型言語の研究&プログラミングの世界には面白いテーマや技術が転がっていて、
せっかくICFPでやるコンテストなんだから、そういうところから面白さを取ってこれると
いいね、と。
頭っからどっぷり関数型言語
な人には当たり前すぎるのかもしれないですけど、例えば最初の方に当たる 「書き換え可能
な変数なし、appendなしでリストの並び順を逆転する簡潔なコードは?」 や 「自然数を
SS..SZ で表して、足し算を項書き換え系で表現」 のような問題は、慣れない人には
なかなか面白い最初の一歩でした。先に進むとsubstructural logicの定理証明
をそのまんまネタにしたゲームが用意されていたり、情報流検査の典型的な
穴をついてシステムを破れ!というクラッキングステージがあったり。そもそも
プログラミング言語を扱う問題が多いので、必要な作業がどれもメタプログラミング
っぽくならざるを得なかったり。他にもCPS変換を応用した問題もあったのだけど
時間の都合で削除したらしく。解いてみたかった…。
といっても、毎年そういう方針で行くのも難しそうでもあり。はてさて。
00:36 06/09/15
GCJ Round1 速報
超だめぽ。
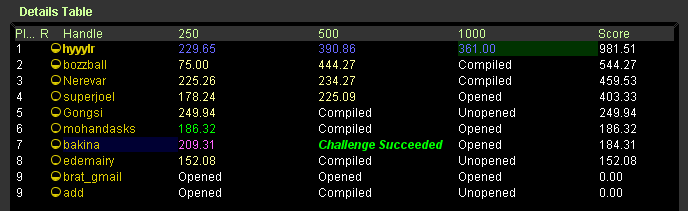
上の人より順位が低いのは撃墜された上に残り30秒で見つけた他人のミスを
撃墜返しに行ったら慌てててミスったせいです。ふがー。
問題の紹介
250点問題。("123/456", 78) みたいな入力が来るので、分母が右側の整数以下の分数で
できるだけ左側の分数に近いものを返しなさい。
下手に浮動小数点数を使うと誤差でエラーったりするかも…と思ってマジメに分数のまま
計算しようとして途中で面倒になってやめたりしたので、そのせいでシステムテスト
落とされる可能性が。近い値が2つあるときは小さい方を選べという指示で、その
選び方を間違ってる(と思う)人がいたのでChallenge してみたら別のルールに
拾われてそのバグが顕在化しないような例を入れてしまった…orz
500点問題。自然数kを2進数と思いきや各桁は0,1,2が使える進数で表現した場合、
何通りの表し方があるか? 例えば10なら"1010", "210", "1002", "202", "122" の5通り。
なんか色々試行錯誤した上に間違えてたわけですが、
人のコードをみて3行で解けることを知って愕然としました。なるほど… orz
1000点問題。0~9の整数のリスト(長さ50以下)と、目標整数値が一つ与えられます。
リストの値をいじって、全部かけ算したら目標値になるように変えたい。
最小で何個値を変えれば目標値にできるか? 例えばリストが [2,4,8] で目標値が 8
だったら、8を1に変えればいいので答えは1(1個変えればいい)。
全然解き方思いつかず orz
まあ
実力相応というか。反省々々。
結果
Failed system test of 250-point problem with arguments ["29/70", 10]:"3/7"
はいはい誤差誤差わろすわろす。
>>> abs(29.0/70.0 - 3.0/7.0)
0.014285714285714235
>>> abs(29.0/70.0 - 2.0/5.0)
0.01428571428571429
ご覧の通り 2/5 の方が遠いんですよ!ってダメダメだなあ。
21:20 06/09/13
PPLサマースクール
昨日は これ
に参加。講義自体はわりと知っている内容だったので、ぼーっと気楽に聞いてました。
とりあえず今回の収穫はバンビでサーロインステーキ定食
を頼む人を初めて目撃できたことです。
しっかし最近書くことがなさすぎて困る。
02:20 06/09/12
未踏ユース
今頃になってとつぜんふらっと
公募結果 を見てみたら、例年になくリアル知り合いのプロジェクトが多くて
(といっても3つだけど)ちょいびっくり。年齢的にそんなもんなのだろうか。
みなさん頑張ってください。
15:49 06/09/08
DanoMoi と Haskell
モナドとかそういうのはどーでもいいので、純粋関数型言語であるところの Haskell
がどうやって入出力してるのか把握したい、という人向けの限りなく適当な解説を試みます。
決して「実際にそういう実装/理論になっている」という話ではなく、「こういう風に
考えとけばわかる気がする」みたいな話なのでよろしくお願いします。
- Haskell プログラムには、一切いかなる意味でも副作用は存在しない
- Haskell プログラムは、"DanoMoi" というプログラミング言語のプログラムを生成する。
yaccプログラムがCプログラムを生成するのと同じ。Cは副作用だらけだけれど、yacc
に副作用はない(つまり同じyaccプログラムを実行したら常に同じCプログラムが出てくる)
のと同じように、"DanoMoi" には副作用がありまくるけれど、Haskell には副作用はない
(同じHaskellプログラムを実行したら常に同じDanoMoiプログラムが出てくる。)
"DanoMoi" という名前および概念は今私が勝手に考えたので適当ですよ。
例えば次のようなHaskellプログラムのmain関数を実行すると、
-- Haskell
main = putStrLn "Hello, World."
↓
// DanoMoi
System.out.println( "Hello, World." );
常に同じ↑というDanoMoiプログラムが生成されます。
別の例として、次のHaskellのmain関数を実行すると、
-- Haskell
main = getLine >>= (\x -> putStrLn (map toUpper x))
↓
// Danomoi
String str = System.in.readLine();
evalDanoMoi( evalHaskell('\x -> putStrLn (map toUpper x)', str) );
常にこうなります。2行目がちょっとややこしいですね。実際にこのDanoMoiプログラムを
動かしたところを想像してみましょう。まずは1行目
String str = System.in.readLine();
いきなり標準入力待ちに入ります。"Hello" と入力したことにします。変数strの値が "Hello"
になります。で次の行。
evalDanoMoi( evalHaskell('\x -> putStrLn (map toUpper x)', str) );
まず内側のevalHaskell関数を実行します。その名の通りHaskellのプログラムをevalする
関数です。最初に言ったように、HaskellのプログラムはDanoMoiのプログラムを生成します。
特に putStrLn "HELLO" は System.out.println("HELLO"); という DanoMoi プログラムを生成
しますので、evalHaskellの結果は
evalDanoMoi( 'System.out.println("HELLO")' );
こうなります。あとはevalDanoMoiが中身をDanoMoiプログラムとして実行すると、画面に一行
HELLO と出てきます。
まとめると
- putStrLn 関数は、一行画面に出力する関数ではありません。
'System.out.println( ... );' というDanoMoiプログラムを作成する関数です。
- getLine 関数は、一行入力を読み取る関数ではありません。
'String .. = System.in.readLine();' というDanoMoiプログラムを作成する関数です。
- >>= という演算子は、
左の処理を実行してから右の処理を実行する演算子ではありません。
左オペランド ++ '\n' ++ 'evalDanoMoi(evalHaskell(' ++ 右オペランドの文字列表現 ++ '));'
というDanoMoiプログラムを作成する関数です。
んでもって
- あなたが「Haskell処理系」と思っているものは、実は evalHaskell
という組み込み関数を持った「プログラミング言語DanoMoiの処理系」です。
- DanoMoiプログラムの実行は evalDanoMoi( evalHaskell( 'main' ) ); から始まります。
おしまい。
一応モナドの話
「Haskellの副作用を一手に引き受けている」と言われるIO a型や、>>=
演算子にすら、副作用はありません。上の例で見せたように、奴らはしょせんはただの
文字列操作です。「Haskell プログラムには、一切いかなる意味でも副作用は存在しな」くて、
副作用があるのは DanoMoi の方ということになります。
所詮はただの文字列操作なら…モナドだのなんだの言わずに、そう実装すればいいじゃん、
とお思いになるかもしれません。それはもちろん可能ですが、しかし、単純に、
面倒くさいのが問題です。DanoMoiのコードを二つ連結するたびに毎回
'evalDanoMoi( evalHaskell(' ++ ... ++ ') )' と書くのは手間ですから、
その辺の定型処理はライブラリ化しないといけませんよね。あと実は、上の例では ... と
省略して逃げましたけど、DanoMoi プログラム内でどういう変数名を使うかとか
衝突しないように調整するのも面倒です。そういう面倒くさい部分を全部ライブラリ化して、
簡単にDanoMoiプログラムを生成できるようにしたのが、instance Monad IO、
なのです。
Haskell には副作用がないので、evalDanoMoi 関数をHaskellで書くことはできません。
なので、DanoMoiプログラム中の値をHaskellで使いたいと思ったら、DanoMoiから
evalHaskellを使って呼び出してもらう他はありません。これが、一度IOモナドに
入ったら出られない現象の理由です。
(実際には裏技として、evalDanoMoi関数は unsafePerformIO という名前で Haskell
から使えてしまうのですが、素人にはお勧めできない諸刃の剣であります。
巧く使うと きわめて便利
らしい。)
実装など
で、まあ本当に文字列表現で作ったりevalで実行したりしてたら遅くてかないませんので、
現実の実装はHaskell処理系とDanoMoi処理系がかっちり組み合わさって効率的にIO処理
できるようになっています。というか↓のdoio関数を正格に実行するだけと思えば、
特に何も効率の悪いところはないというのがわかるのではないかと。
data IO a = getLine | putStrLn String | (>>=) (IO a) (a -> IO b) | ...
doio (a >>= b) = let x = doio a in doio (b x)
doio (getLine) = 標準入力から一行読んで返す処理
doio (putStrLn s) = 標準入力にsを出力する処理
doio main
だんだん説明が適当になってきたので今度こそおしまい。
ちゃんとした説明はnobsunさんの記事「HaskellのモナドIO」
がよいです。
01:12 06/09/07
Google Code Jam 2006

Google Code Jam 2006 の予選の日でした。Google が毎年やってるプログラミング
コンテスト powered by TopCoder です。予選はアルゴリズムクイズっぽいものを2題解け
というもの。制限時間1時間で、速くコード書けば書くほどスコアが上。もちろん間違って
たら0点です。いまちょうどコーディングタイムが終わったところで、次にシステム側の
自動チェックが走ります。自分のスコアがどうなるかドキドキです。
今年は例年の C++, Java, C#, VB.NET に加えて Python
が使えるようになっていたので、にわか Python 使いとしましては挑戦せざるを得ません。
たとえ注意書きで
All submissions have a maximum of 2 seconds of runtime per test case. ... Because the inherent speed differences between Python and the other offered languages is large, some problems may require extra optimization or not be solvable using the Python language.
※ 1テスト通すのに2秒以上かかるプログラムは失格だよー。
Python だけ他の言語と比べて言語自体が遅いから、Python 使ってると解けなかったり、
気合い入れて最適化しないとダメなことがあるかもねー。(意訳)
と書かれていようとも。とはいえ本当にそこまでキツくはないだろう…と思いつつ
練習コーナーの問題を解いてみたらC++で0.4秒で解ける問題がPythonだと自分の腕では
どう頑張っても通せず挫折しようとも。思わず "Python 高速化" で検索かけて知った
Psyco (Python JIT コンパイルライブラリ)
を入れたら、手元でC++版より速くなって驚愕しつつTopcoderにPsycoインストールして
下さいと直訴したくなろうとも。(マジメな話、これは入れた方がいいんじゃないかなあ…)
問題
私にassignされた250点問題(簡単な方)は、サッカーの試合で審判が出した
イエローカードとレッドカードの履歴を文字列のリストで渡すので、イエロー2回
出したのにレッド出し忘れてるミスを見つけたらそれを警告しなさいとか言う、
まあ書いてある通りに解くだけ問題。→ gcj06_q250.py
(辞書にリストを貯めてく部分と最小値計算のコードがいまいち美しくない感じ。
Pythonでこれをうまく書くイディオムとかありそう…。あ、最小値は内包表記使うといいのか?)
errs = [t[1] for n, t in yellow.iteritems()
if len(t) >= 2
if "R %02d %s" % (t[1],n) not in info]
if errs: return min(errs)
return -1
750点問題(難しい方)は、N×Nの正方行列に対して、Permanent という値を計算せよ
というもの。ただしNは16以下。行列式みたいに高速に解けるのかなーと数秒考えて
思いつかなかったので力押しすることに決定。今調べたリンク先の情報によれば
多項式時間のアルゴリズムは知られていないらしいので、まあこれでいいんだろう…。
力押しと言っても順列を16!通り全部試したら何日かかっても終わらないので、
メモ化を入れてスピードアップしてやります。
→ gcj06_q750.py。
これで一件落着…と思ったら、16×16サイズの行列で試してみると実行時間がほぼ2秒。
運が悪いと制限時間アウトで落とされそうです。えーとTopCoderさんPsyco入れてください。
仕方がないのでメモ化処理を汎用版をやめて直接埋め込んだり、メモ表の構造を多少いじって
20%高速化。これでなんとか通る、かな。まあ、そもそもコードが間違ってたら泣けますが…。
Python
↑は遅い遅いと文句いってますが、コードを書くの自体はとても楽で、
プラスマイナスで言えば個人的にはプラスです。関数内関数も内包表記もスライスも
アンパック代入も(後ろに行くほど重要)やっぱしあると便利。Round 1 にもし行けたら次も
Python で。
02:58追記
750点問題システムテストで落とされてるるるる…。でも一応通ったかな?
ひとのソースが見られるようになってるので見て回ってます。
そうか添え字候補をタプルでなんか持たずに16個のbitで持てば、
メモは配列にできるし候補消しもxor一発だ。そりゃそうだああああ…
# 違うそれ以前に matrix will contain between 1 and 16 elements,
inclusive かつ Each integer in matrix will be between 0 and 10000,
inclusive だ!
私のコード、1×1 の (10000) っていう行列が来たときだけ答えを間違える。
馬鹿だw。テスト作るときは必ず全て境界例は入れておけと、もう、
何回やれば気が済むのか>俺。
