17:05 06/01/21
It's snowing.
 雪ー。写真でも撮ろうかと思い家を出ましたが寒いので徒歩6秒のところで引き返しました。
雪ー。写真でも撮ろうかと思い家を出ましたが寒いので徒歩6秒のところで引き返しました。
yellowTAB が Berry Japan との契約を解除、って、なんじゃそりゃ。 私は PC-CRAFT 経由で買ってたの ですが、これも切った方のルートに含まれてるのかな。うーむ。
第一稿submit!やほー!学科内発表も最終稿締め切りもまだまだ先に控えてますが、 だいぶ気が楽になりました。
Re: Block Tower。
同じ直方体を2度通らない
という制約が、簡単そうに見えてなかなか厄介に思えます。
普通のダイクストラ法なら各頂点でそこまでの最短経路さえ覚えとけば済むんですけど、
同じ直方体を2度使わないようにするためには、各頂点ごとに
「ある直方体Xを通う最短経路」「使わない最短経路」を両方計算しておく必要が
あって、それを計算するには「直方体X,Yをどっちも使わない経路」やらなにやら、
理論的には最終的に全ての頂点集合2n個について、それを使わない
最短経路が入用になったりと。
あーでも、実際にはほとんどの「使わない経路」は共有できるからうまくやれば行けるかな?
古くから、風が吹くと桶屋が儲かるとは申しますが、それとは全然関係なく、 私に締め切りが近づくとAmazonが儲かるという怪現象が。これ今月何冊目だ。 向井さんの紹介を見て興味を持った『考える脳考えるコンピューター』、他いろいろ入手。 パラパラとめくってみたところ "サールの部屋" が肯定されているのが目に入って、 それはつまり今の自分の考え方とは逆の立場からの議論ということで、なかなか面白そう。
おとといリンクしたHoneyBeeBrandのつながりをたどりまくって全部書評を読破してしまいました。 読んだことのない本で、しかも興味を持てそうなものが多くてかなり楽しいです。 他の人の書評やあるいは蔵書のリストなんかを見たときに、知ってる本ばかりだと 親近感は湧けども新しい発見は少ない。逆に全然自分の興味のない分野の話ばかり だと、これはこれでつまらない。そのどちらでもない本ばかりが揃っている驚異の 本棚にはこれまで一度しか出会ったことがなくて、ていうか 本棚.orgの増井さん本棚 なんですけど、これは凄いなあ、と感激したものです。上記のサイトの書評リストも、 それに匹敵する凄いなあ感が。
Bamboo といえば上野の Bamboo Garden というお食事処の階段が駅から公園への抜け道になってることを最近知りました。 自宅 ⇔ 上野駅の直線ルート上にあるのでかなり便利。ガラス張りに竹という 組み合わせもなかなか見てて飽きないし、最近のお気に入りの道です。
なぜか封印しているはずのhatenaが見えてしまった、これはスーパーハカーの仕業に 違いない……と言い訳になってない言い訳をしつつ、 「時」をテーマにした小説 という面白そうな質問があったのでなんとなく考えてみます。
回答にあがってないものだと… 『異邦人』 がまず思いつきます。西澤保彦というのは 同じ日を何回も繰り返し過ごせてしまう特異体質の少年を探偵役に据えてみたり、 他人と心と体が入れ替わってしまった!という状況で殺人事件を起こしてみたり、 現実には絶対ありえないような設定をひとつ持ち込んだ上でのミステリを好んで書く 人で、中でも私が一番好きなのが「主人公がタイムスリップして23年前に父が殺された事件を 防ごうとがんばる」というこの作品。Amazonのレビュー書いてる人と自分はもしや違う 小説を読んだのではないかと不安になるくらい逆の感想ですが、この"現実にはありえない設定" を完璧にフェアに使いこなしているし、ミステリの道具としてこの"タイムスリップ しちゃった主人公"という特徴を必要不可欠なピースにすることに成功しているのが完璧。 (逆に同じ作者の代表作の「七回死んだ男」なんかは、別に七回死ななくても いいじゃん、と思えてしまう辺りがどうも。)
あとは 『たんぽぽ娘』。日本語訳が収録された短編集はどれも絶版らしい。 「240年の未来からやってきました」という女の子と出会って云々、という タイムマシンを使った恋物語SFなのです。なんというかメビウスの輪のような、 ちょびっと切って貼り直しただけで、これだけ素敵な時間の流れ方が作れるのだなあと 感心しました。それと、微妙に関係ないですが、タイトルで検索かけてみたら HoneyBeeBrand という面白いサイトを発見。「○○つながり」というページ単位でまとめて 本の紹介がたくさん載ってます。そこの 時を越える事件つながり を見てみると一作品も読んだことなかったので、今度探してみよう。
あとは…SFやファンタジーから"時を越える"やつは色々思いつくけど、他の ジャンルでは何も出てこないなあ…書いてれば何か思い出すかと思ったのだが。うむむ。
『Bamboo Blade』 2巻げっと。 ヤングガンガンて、読まないと人生損してると 思うほど熱烈にオススメなわけではないけど読んでるとなんだか落ち着くいい按配な 面白さ、みたいに感じる連載が多くてなごみます。今のところこれと『荒川~』を揃えてまして、どちらもコミックを買ったその日に気づくと5回くらい 読み返してて危険。
dmd の GC を弄ってたら唐突に、全然関係ない GreenPad のすんごいバグに 気づきました。いや、Undo/Redo を繰り返してると時々、されるべきでないところで dirty flag がクリアされてるような気がするなーと前々から薄々思ってはいたのですが。
現状、端っこの処理などの本質的でないとこを除くと、Undo/Redo 周りはこういう風な 構造になってます。
class Command {
virtual Command* exec() = 0;
// なんか処理して、その処理結果をUndoする逆操作Commandをreturn
};
class Undo_Redo_Chain {
class Node {
Node* prev;
Node* next;
Command* cmd;
Node(Node* prev, Node* next, Command* cmd) {...}
~Node() { delete next; }
};
Node* lastOp; // 最後に実行したコマンドに対応するNode
Node* savedPos; // ユーザーが保存した時点
public:
void redo() { lastOp=lastOp->next; lastOp->cmd=lastOp->cmd->exec(); }
void undo() { lastOp->cmd=lastOp->cmd->exec(); lastOp=lastOp->prev; }
void newly_exec(Command* c)
{ delete lastOp->next;
lastOp = lastOp->next = new Node(lastOp, 0, c->exec()); }
void notify_save_event() { savedPos = lastOp; }
bool is_changed() { return (savedPos != lastOp); }
};
今なら、せっかくC++なのになんで自前で delete なんて
書いてるのだねチミは?と一蹴するような造りですが、まあ若気の至りということで許して
下さい。自分でも書いてて恥ずかしいので。あと、この双方向リストのdestructiveな
使い方気持ち悪いと思ってしまうようになった辺り、関数型言語に毒されてるなあ。
まあ、それはともかく、 is_changed が true か false かで、変更済みかそうでないかを判定してます。 で、変更されてたら終了時には保存しますかと問い合わせたり。保存→コマンド→Undo のパターンでは変更済みフラグが消えるようにしたかったらしい。
問題は、コマンドA→保存→Undo→コマンドB とやった場合。この場合は普通は
"変更済み" にならないといけません。なのですが、最後のコマンドBを
newly_exec する時に、「1:delete で lastOp->next、つまり savedPos の指すオブジェクトが
開放される」→「2:new Node に対して、メモリアロケータが
さっき開放されたメモリ領域をすかさず再利用」というコンボが決まると再び
savedPos==lastOp になってしまって "未変更" 扱いに。だめぽ。
savedPos は決して参照外ししないから開放済み領域を指すことがあっても問題ないので、 ここはスマートポインタ使わなくていいや、とか愚かなことを考えてた昔の自分が うっすらと思い出されます。ぁぁぁぁぁぁぁぁ。赤面。2月の頭には修正版出します。
"内包表記" を変換しようとしたら "無いほう表記" と出て、 意味深だなあと思いかけたけれどよく考えたらそうでもない気がする。
"Haskell is not not ML" ていう論文のタイトルが巧すぎて感動しました。
『Hybrid Insector』を読みました。ネタ元であるところの仮面ライダーは ファミコンのゲームで知ってるくらいで実は一度もテレビで見たことなくて ストーリーも全くわからんのですけど、原作でも "Hybrid" が重要なテーマ なんですかね。他に自分の知ってる同じモチーフの作品『Hyper Hybrid Organization』も "Hybrid" を主軸にしていたので。なんだかオリジナルの仮面ライダーの 方に興味が湧いてきました。
シザーマンとか出てくるやつ、じゃなくて。 これと同じ頃から頭をひねってる問題がもうひとつ ありまして。
N個の直方体のブロックがあります。このN個から何個か選んで できるだけ高く積み上げたい。ただし、
- 幅A×奥行B×高さC のブロックの上に 幅D×奥行E×高さF のブロックを積む場合は、 A>D かつ B>E でないとバランスが悪いのでダメとします。
- 幅A×奥行B×高さC のブロックを 幅B×奥行A×高さC として使ってもいいし、 幅C×奥行A×高さB として使ってもいいし、とにかくまっすぐ置くならどの向きで 使ってもOKです。でも斜めに置くのは禁止。
- 同じ形のブロックは1個ずつしかありません。
という条件で。
例えば (1,2,3) (1,3,4) (2,3,3) (1,3,3) の4つだったら多分 幅4*奥3*高1 の上に 幅3*奥2*高3 の上に 幅2*奥1*高3 で 合計高さ7にして残りの1個は使わないでおくのが、多分ベスト。実はちょっと自信ないけど。
この問題も、片っ端から積み方を全部試していけばいいので、解くだけなら解けます。が、 ブロックが1000個や2000個になると全通りの積み順を試すのは大変。ブロックの個数 N に比例する時間か、せめて多項式時間で最適解を見つけるアルゴリズムは無いものか?
ネタ元は IOPC 2005 の Problem 11。元々の問題は"同じ形のブロックを何個でも使っていい"という条件なので 物凄く簡単になっているのです。3*2*1 の上にもう一度自分を 2*1*3 の形で置いちゃわ ないように気をつける必要がないので、簡単に探索できる。この条件を取っ払ったら どうなるかなーと考えていたのですが、どうも上手い手が思いつきませんでした。
雪ー。写真でも撮ろうかと思い家を出ましたが寒いので徒歩6秒のところで引き返しました。
yellowTAB が Berry Japan との契約を解除、って、なんじゃそりゃ。 私は PC-CRAFT 経由で買ってたの ですが、これも切った方のルートに含まれてるのかな。うーむ。
昨日のは場合分けに漏れが激しかったので全然ダメでした。えーと、これでどうだ。 正規表現パターンマッチがあるととても楽なのだけど処理系が手元に何もないので 今でっちあげた脳内言語で書くとこんなの。意味は適当に推測してください。 誰か OCamlduce で書いてみるとよいと思う。
// reduce
// 連続していなければならない要素の集合 constraint をうけとって、
// その制約を加えた新しい PQTree を作って返す。
// 途中計算用の型 Result のタグの意味は
// W : constraint に入ってないLeafしか含まないノード (White)
// B : constraint に入っているLeafしか含まないノード (Black)
// WB : その順序で並べると、先頭側がWhiteで末尾側がBlackになっているノードリスト
// WBW : Whiteノードに囲まれる形で奥のほうにBlackノードがあるノード
// 関数fでは再帰的にBottomUpにこのResultを計算して、それに基づいて適当に頑張る。
// 例えば P の子ノードの計算結果が W WB W W B WB B だったら、
// P(W W W Q(WB P(B B) WB.rev))
// というノードを作ってやればこれはWBWノードになっている、とか。
// W,B,WB,WBW のどの形も作れなくなったら、例外を投げて失敗を知らせる。
type PQTree = P(PQTree*) | Q(PQTree*) | Leaf(Any)
type Result = W(PQTree) | B(PQTree) | WBW(PQTree) | WB(PQTree*)
reduce :: ( constraint:Set, root:PQTree ) -> ( :PQTree ) =
match f(root) with
W(p) | B(p) | WBW(p) -> p
WB(ps) -> Q(ps)
where
f :: ( t:PQTree ) -> ( :Result ) =
match t with
Leaf(e) -> if constraint.contains(e) then B(t)
else W(t)
P(ps) -> match sort(map(f)(ps)) with
B(_)* -> B(t)
W(_)* -> W(t)
W(a)* WBW(b) -> WBW(P(a b))
W(a)* B(c)* WB(b)? -> WB(P(a) b P(c))
W(a)* B(c)* WB(b) WB(d) -> WBW(P(a Q(b P(c) d.rev)))
_ -> raise "No Solution"
Q(ps) -> match map(f)(ps) with
B(_)* -> B(t)
W(_)* -> W(t)
W(a)* WB(b)? B(c)* -> WB(a b c)
B(a)* WB(b)? W(c)* -> WB(c.rev b a.rev)
W(a)* WB(b)? B(c)* WB(d)? W(e)* -> WBW(Q(a b c d.rev e))
W(a)* WBW(c) W(e)* -> WBW(Q(a c e))
_ -> raise "No Solution"
とか書きつつもう少し探してみたら、 "PC Trees vs PQ Trees" (PDF) に載ってました。 方針としては大体あってたみたい。回転なしでBottomUpに変形していけば十分らしい。 しかし↑の場合分けで足りてるかどうかは論文の図を見ても自信がもてない。 PC-Tree というのはルートを固定しないで考えると上の大量の場合分けの必要がなくなって 簡単になるよという改良版らしいのですが、だんだん興味が失せてきたのでこの辺でおしまい。
何日か前の話の続き。 PQ Tree は、「Pノード」「Qノード」「リーフ」の三種類のノードからなる 木構造である。木の形を使って、リーフの並べ方に関する条件を表す。
例えば P(1 2 3 4 5) は、12345も13425も25431もどの並び方もOKという条件を表す。 Q(1 2 3 4 5) は、12345か54321のどっちかならOKという条件を表す。 P(1 2 Q(3 4 5)) は、12345, 12543, 13452, 15432, 34512, 54312, 21345, 21543, 23451, 25431, 34521, 54321 の12種類の並べ方をあらわす。
…… PQ Tree と連続させたい要素の集合とを与えると、その増やした制約を 反映した新しい PQ Tree を返す "Reduce" アルゴリズムというのがあるらしいのですけど、 ちょっと探した範囲で実装方法が見つからなかったので、試しにこんなもんでどうだろう?と 適当に作ってみました → pqtree.d。 多分間違ってるので注意。他の文献からはかなり複雑なアルゴリズムと 言及されてるので、こんなに適当じゃ多分ダメでしょう。制約を入れるときに木構造の 細分化しかしてないので、きっとどこかに回転みたいな操作が必要になるんじゃないかと 思います。
そして自分はこんなことしてる場合ではないのです。
主に "Scarborough Fair" のカバー目当てに 『眠る孔雀』 買いました。元々の英語詞に変えてところどころがオリジナルの日本語詞になっている (そして両者は一見全く別のストーリー)という構成は、Simon & Garfunkel の例に 倣ったのでしょうかね。他には "tell me how"、"空の出口" 辺りもなかなか好きでした。 上のリンク先で全曲試聴できるので、みなさまもぜひ。
『いわせてみてえもんだ』 というマンガを知って読みふけってしまいました。つ、つづきが気になる…!
あと 猿でもわかる水玉潰し を見てふむふむなるほどと思い 「小さな水玉を多少強引に大きくしてでも中央から発火」の方針でやってみたら、 いきなりLV25に!(これまで自己ベストLV16でした。)
そしておかげで今日は修論1ページも進まなかった! ちょっともう本当にヤバいので今月末まで *.hatena.ne.jp と 1470.net と blog.livedoor.jp は絶対見ないことにする。今 hosts ファイル書き換えた。よし。
GPLv3 Draft、 あとでちゃんと読む…相変わらず長いー。
ある単語で検索してたら 『博士の愛した数式』 のエピソードが大量に引っかかってなんじゃこれー?と思いながらふと思いついて google://博士の異常な数式。5件。 もっといるかと思った。ほんとどーでもいいですすみません。
LtU 経由で "Efficient subtyping tests with PQ-encoding" という論文を知りました。 あるクラスが別のクラスの派生クラスかどうか実行時に判定するための効率的な実装の話。 ダウンキャスト/クロスキャストが安全にできるかのチェックとか、
class MyClass {
int compareTo( Object o ) {
if( o instanceof MyClass ) // o.getClass extends MyClass?
...
}
}
どのcatch節で例外を捕まえるべきかの判定とか
try
...
catch( HogeException e ) // 飛んできた例外がHogeExceptionか
... // その派生クラスのインスタンスだったらcatch
catch( FugaException e ) // 飛んできた例外がFugaExceptionか
... // その派生クラスのインスタンスだったらcatch
そういうところで必要になるお話です。この問題の多重継承があるときの効率のいい 解決策をこれまで知らなかったもので、なんか既存手法の辺りからもう感心しながら 読んでました。ちょっとまとめてみます。
実行時のクラス情報をあらわすデータに、親クラスのクラス情報へのポインタを 入れておいて、ループをまわして先祖を全部たどって確かめる。
class ClassInfo {
ClassInfo parent;
...
}
boolean is_descendant_ancestor ( ClassInfo ta, ClassInfo tb ) {
for( ClassInfo c=ta; c!=null; c=c.parent )
if( c == tb )
return true;
return false;
}
わかりやすくて良いのだけど、階層の深いところにあるクラスから判定しようと するほど時間がかかる。多重継承がある場合parentもひとつじゃなかったりで大変。 実行時に毎回たどる手間を省くために、各クラスごとに「祖先全部」をハッシュか バランス木で記憶しておく手もあるけれど、これはメモリを喰う。
コンパイル時に(クラス数+インターフェイス数)2 のテーブルなり マップなりを作っておいて、実行時にはその表を引く。確かに実行時は速いのだけど メモリ馬鹿喰い。
Map<ClassInfo, Map<ClassInfo, boolean> is_descendant_ancestor;
多重継承は考えないことにすると、クラス階層は、木構造になる。
A-+--B-+--E
| +--F
| +--G
+--C
|
+--D-+--H
+--I
親から行きがけ順に番号を振る。
A(1)-+--B(2)-+--E(3)
| +--F(4)
| +--G(5)
+--C(6)
|
+--D(7)-+--H(8)
+--I(9)
すると、Aの派生クラスは[1-9]、Bの派生クラスは[2-5]、Cの派生クラスは[6-6]…、 と、どのクラスから見ても自分の子孫の番号は、ひとつの区間におさまる。ので、 各クラス毎に2個ずつだけ整数を覚えておけば、2回の比較で判定ができる。 メモリもほとんど喰わない。しかも速い。お得。
class ClassInfo {
int range_begin; // == id
int range_end;
...
}
boolean is_descendant_ancestor ( ClassInfo ta, ClassInfo tb ) {
return tb.range_begin <= ta.id && ta.id <= tb.range_end;
}
しかし、多重継承(Interfaceの多重継承も含む)に対応できなかったり、実行時にクラスを ロードして増やすような場合(Javaとか)、あらかじめ全てのクラスに番号を振っておくことが 難しいので単純にはうまくいかない。
まだ多重継承は考えない。各クラスは、自分が継承階層のルートから数えて何層目に 位置しているかわかるので、その値(levelと呼ぶ)を覚えておく。
A[0]-+--B[1]-+--E[2]
| +--F[2]
| +--G[2]
+--C[1]
|
+--D[1]-+--H[2]
+--I[2]
例えばクラスEに着目すると、Eのlevel0先祖はA。level1先祖はB、 level2先祖は自分だけど一応、E。単一継承を仮定しているので、自分の levelは一意に決まるし、自分のlevelX先祖も一意に決まる。というわけで、 levelをインデックスにして先祖一覧の配列を持っておけば、一発でアクセス可能。
class ClassInfo {
int level;
ClassInfo[] ancestors; // size == level+1
...
}
boolean is_descendant_ancestor ( ClassInfo ta, ClassInfo tb ) {
return ta.anscestors[tb.level] == tb;
}
「とても単純な方法1」をエレガントに実装した感じですね。メモリは各クラス毎に 先祖の個数分+1くらい喰うのでRelative Numberingよりは劣りますが、判定にかかる 時間は同等程度に効率的ですし、なにより、実行時にあとから他のクラスをロードしたときにも、 既にあるクラスのlevelやancestorsを変更する必要がないので、簡単に拡張できます。 (インクリメンタルである、というらしい)
Cohen's Encoding を多重継承対応にすべく考えられた方式。 Cohen's Encoding の方法をじっくり見直してみると、特に「level」をインデックス にする必然性はないことに気づく。要は、どのクラスにとっても、全ての先祖に違う 番号が割り振られていれば、その番号をインデックスとしてancestors配列を作ればよい。 単一継承の場合はたまたま「level」が常にこの条件を満たしているだけ。
例えばこんなクラス階層(だんだんAAだと意味がわかんなくなってきましたが、 さっきまでの例に加えて、BとCをJからも派生させて、HはDとIを多重継承)を考えると
A[ ]---+------+-B[ ]-+--E[ ]
| | +--F[ ]
J[ ]-- | -----+ +--G[ ]
| |
+------+-C[ ]
|
+--------D[ ]-+-----H[ ]
| /
+--I[ ]
levelで番号を振るとダメ。というわけで、上手い番号付けを気合で考えます。 E,F,G,Hのancestorsが4つあるので、最低でも4種類の番号が必要ですが、
A[3]---+------+-B[1]-+--E[2]
| | +--F[2]
J[0]-- | -----+ +--G[2]
| |
+------+-C[1]
|
+--------D[0]-+-----H[1]
| /
+--I[2]
適当に例えばこんな感じに決めれば、四種類で足りました。
class ClassInfo {
int color;
ClassInfo[] ancestors; // size == max(color)+1
...
}
boolean is_descendant_ancestor ( ClassInfo ta, ClassInfo tb ) {
return ta.anscestors[tb.color] == tb;
}
最悪全クラスに異なる番号を振れば条件は満たします(この場合、「とても単純な方法2」と 同じことになる)。が、当然、出来るだけ少ない番号で分類できた方がメモリ効率がよい。 ところが、一般にこの手の階層構造が与えられた時に分類に必要な最小の数を求める 問題はNP-hardらしく、ここはできるだけよい解を頑張って探す、という近似アルゴリズムで 実装するしかないそうです。あと、Cohen's Encodingのインクリメンタル性はこのままだと 失われてしまってる、かな。
最初に紹介した論文で導入された手法。こちらは Relative Numbering の方法を じっくり見直して改良したもの。Relative Numbering の説明を見直してみると、 「木構造の行きがけ順でつけた番号」であることに必然性はないことがわかる。 要は、どのクラスにとっても、子孫全ての番号が連続して割り振られてさえいれば、 その子孫区間を二つの整数で表現すればいい。単一継承の場合は行きがけ順で よかったけれど、多重継承の場合も、そういう番号付けを頑張って探せばOK。
A(7)---+------+-B(2)-+--E(3)
| | +--F(4)
J(1)-- | -----+ +--G(5)
| |
+------+-C(6)
|
+--------D(8)-+-----H(10)
| /
+--I(9)
たとえばこんなの。Aの子孫は[2-10]、Jの子孫は[1-6]、Bの子孫は[2-5]、Dの子孫は[8-10]、 …。
class ClassInfo {
int range_begin;
int range_end;
...
}
boolean is_descendant_ancestor ( ClassInfo ta, ClassInfo tb ) {
return tb.range_begin <= ta.range_begin && ta.range_end <= tb.range_end;
}
さてやはり問題は、こういう賢い番号付けをどうやって探すかですが…
という条件を全て満たす A~J の並べ方を探索したいわけです。全探索は クラス数! 通りで 不可能。しかしここでなんと、まさに↑の問題を解くための PQ-tree という 効率的なデータ構造がすでにあるそうな。ゲノム方面とか平面グラフ判定とかで使うらしいの ですが、私も今 PQ-tree については調べ中なので実装方法はよくわかりません。 とにかくそういうので実装できましたということだそうな。 あと、複雑に多重継承しているとどう頑張っても上手い番号がつかない場合もあって、その場合は Packed Encoding 同様に color 毎に分割してからそれぞれの color について番号をつける ことになるそうです。この手法もインクリメンタル性はなし。
以上、「levelなのが本質ではなくて、ancestorどうしでインデックスが違ってさえいればいい」 とか「行きがけ順なのが本質ではなくて、descendantで連続してさえいればいい」とか、 言われてみればその通りすぎるんですけど、言われないと考えなかったなあ…と 反省中の k.inaba がお届けしました。
"D" だけだと検索しにくいのでみんなで各ページ1回は "D programming language" と入れておくようにしない? と Walterタン が 提案 してました。まあそうだよね。日本語で検索かける場合は "D言語" があるから 問題ないか。
検索しにくいといえば前々から感じているのが、探索アルゴリズムの "A*法"。 "A-star" でもあまりよい結果はでない。そもそも今、どういうアルゴリズムなのかの 説明代わりにどこかにリンク張ろうと思っても適当なページが見つからなかったぐらい。 うーん。
『Beyond the C++ Standard Library: An Introduction to Boost』 読了。 扱うライブラリをある程度絞って(GraphやuBLASみたいな専門的なのやFilesystem, Date_time辺りの環境に依存する辺りは省いて、Smart_PtrやらAnyやらBind/Lambdaやら を紹介)、詳しめに解説しています。さすがに introduction なので初めて知る話は なくて自分的には少し物足りないですが、入門としてはいい感じ。ノリが妙に軽くて 読みやすい。どの章にも「標準ライブラリとどんな感じに組み合わせるとお得か?」 コーナーがあるので使えるポイントもわかりやすい。
高校のクラス会でした。
親に時々訊かれるときも思うのですが、「今何の研究してるの?」ていう質問に どう答えればいいのか、なかなか難しいな、と。3秒で答えるとなれば3秒なりには 言えるし、逆に3時間かけて説明しろと問われればプログラムとはプログラミングとは なんぞや辺りから始めて、本質に近い理解をしてもらうことも、ある程度はできると思う。 でも3分で語ろうとするとなかなか難しい。完全に説明するのはとても不可能だし、 まあ、そもそもそれが求められているわけでもないけれど。でも、 「なんか本人は面白そうだが何を言ってるのかさっぱりわからない話を聴いた」ではなくて 「なんか他で話したくなるような面白い話を聴いた」と感じてもらえるような うまい切り口があれば楽しいなあ。
あと来年の幹事になってしまったので忘れないようにここにメモ。
ご多分に漏れず水玉潰している わけです。手玉が増える条件がよくわからん。連鎖の幅でも深さでもないですよね。 単純に、一発で潰した個数?3個につき1個、かなあ。実験して確かめようとすると余計な ものが勝手に潰れて大混乱したりしています。現在LV13が自己ベスト。
今まで銀行口座はUFJにしてたのです。が、合併して三菱東京UFJ銀行になりよったせいで 書類に銀行の名前を記入するのが当社比30倍面倒になってしまいました。「菱」なんて生まれて 初めて書いた字のような気がします。最初書けなくて辞書引いたのは秘密です。
去年同様 新年は毎日ここを更新してみようと思ったのだけど早くも書くことがなくなってるのも 秘密です。
受信箱のプロパティで[送信控え]にもチェック付けとくと、受信したメールと 自分の送信したメールを1箇所にまとめられるではないか!今頃になって気づいた!
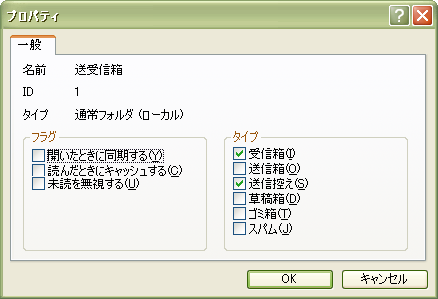
返信の返信の返信…を一連のスレッドとして表示できるのでこれはあると物凄く便利。 そもそも自分の送ったメールだけを一覧したいことってほとんどないし、必要なら 検索でフィルタかければいいわけで、受信箱と送信箱が分かれている必要は 個人的には全然なかったりするもので。なんで今までできないと思い込んでいたんだろう。 悔やまれる。
今頃気づいた!といえば '~' という文字はURIには直接書いてはいけなくて "%7e" とエンコードするのが本当は正しい(めんどくさいからよくサボるけど)と思って いました。ところがD言語スレでstd.uriの話が出てたのを機に RFC 3986 (2005 Jan) を読んでみたら、 '~' は普通にそのまま使っていい文字とされてました。あらら。 ひとつ昔の 2396 (1998 Aug) でも既に使ってよい文字になっていて、 1738 (1994 Dec) まで遡るとやっと禁止されている。2396の末尾に1738からの変更点として、チルダに ついても書いてありますね。自分がこんなことを気にするようになったのは1999年よりは 後だと記憶しているのだけど。なんでだ。
今年もよろしくお願いします。>ALL
全然テレビを見ない、そもそも普段住んでるところにはテレビを置いてないもので 芸能人の顔などの話は全然わからなかったのですが、正月ということで実家に帰ると テレビがある。で、ぼーっと見ていて、なんだか某先輩に似た人が出てるなあ… と思ってテロップを見るとカンニングの竹山という人でした。おお、これが。
